
APEX AI生産性指数が明かす衝撃の真実:AIは本当に仕事を奪えるのか
2025年10月、AI人材プラットフォームを運営するMercorが、AIモデルの経済的生産性を測定する革新的なベンチマークAPEX(AI Productivity Index)を発表した。投資銀行、法律、コンサルティング、医療の4分野で200の実務タスクを評価した結果、最高性能のGPT-5でさえ64.2%のスコアに留まり、「どのモデルも実務タスクの自動化基準を満たしていない」という衝撃的な結論が示された。
この発表は、AIエージェントブームに沸く業界に冷や水を浴びせるものだ。SWE-BenchやMMLUといった既存ベンチマークで高スコアを叩き出すモデルが、実際の経済価値創出では50-60%台の評価しか得られない現実が明らかになった。
APEXとは何か:経済的価値に焦点を当てた新基準
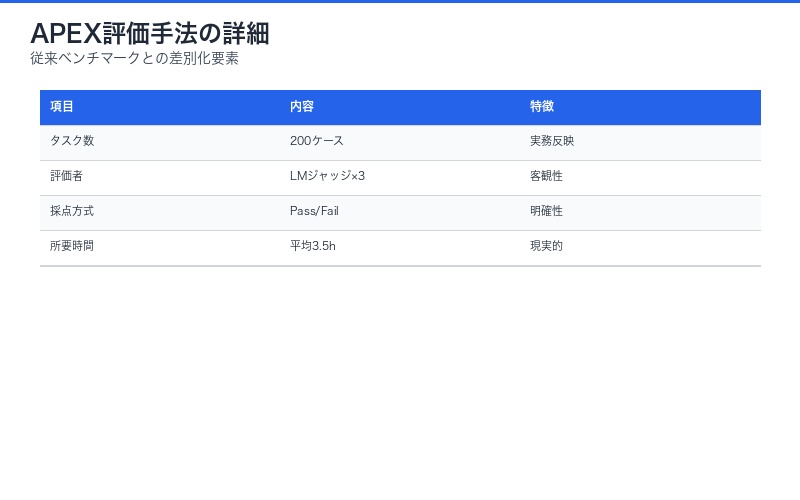
APEX(AI Productivity Index)は、Mercorの研究チームが開発した、AIモデルの経済的生産性を測定する初の包括的ベンチマークである。従来のベンチマークが学術的な能力測定に偏っていたのに対し、APEXは実務での価値創出能力に焦点を当てている。
APEXの基本構成
| 項目 | 内容 |
|---|---|
| 評価タスク数 | 200ケース |
| 対象分野 | 投資銀行、法律、コンサルティング、医療(各50ケース) |
| タスク所要時間 | 平均3.5時間(実務を反映) |
| 評価モデル数 | 23モデル(クローズド13、オープンソース10) |
| 専門家関与 | 約100名の業界エキスパート |
なぜ既存ベンチマークでは不十分なのか
SWE-BenchやMMLUといった既存ベンチマークは、以下の限界を抱えている:
- 学術的偏重:理論的な問題解決能力は測定できるが、実務での適用可能性は不明
- 単一タスク評価:複雑な業務プロセス全体の遂行能力を測定できない
- 経済価値の欠如:ベンチマークスコアと実際の生産性向上の相関が不明確
- 時間軸の無視:実務タスクに必要な時間を考慮していない
Mercor研究チームの見解:
「既存のベンチマークは、AIが何ができるかを示すが、AIが経済的にどれだけ価値を生み出せるかは示さない。APEXは、この重要なギャップを埋めるために設計された。」
– Brendan Foody、Osvald Nitski、Bertie Vidgen(APEX開発チーム)

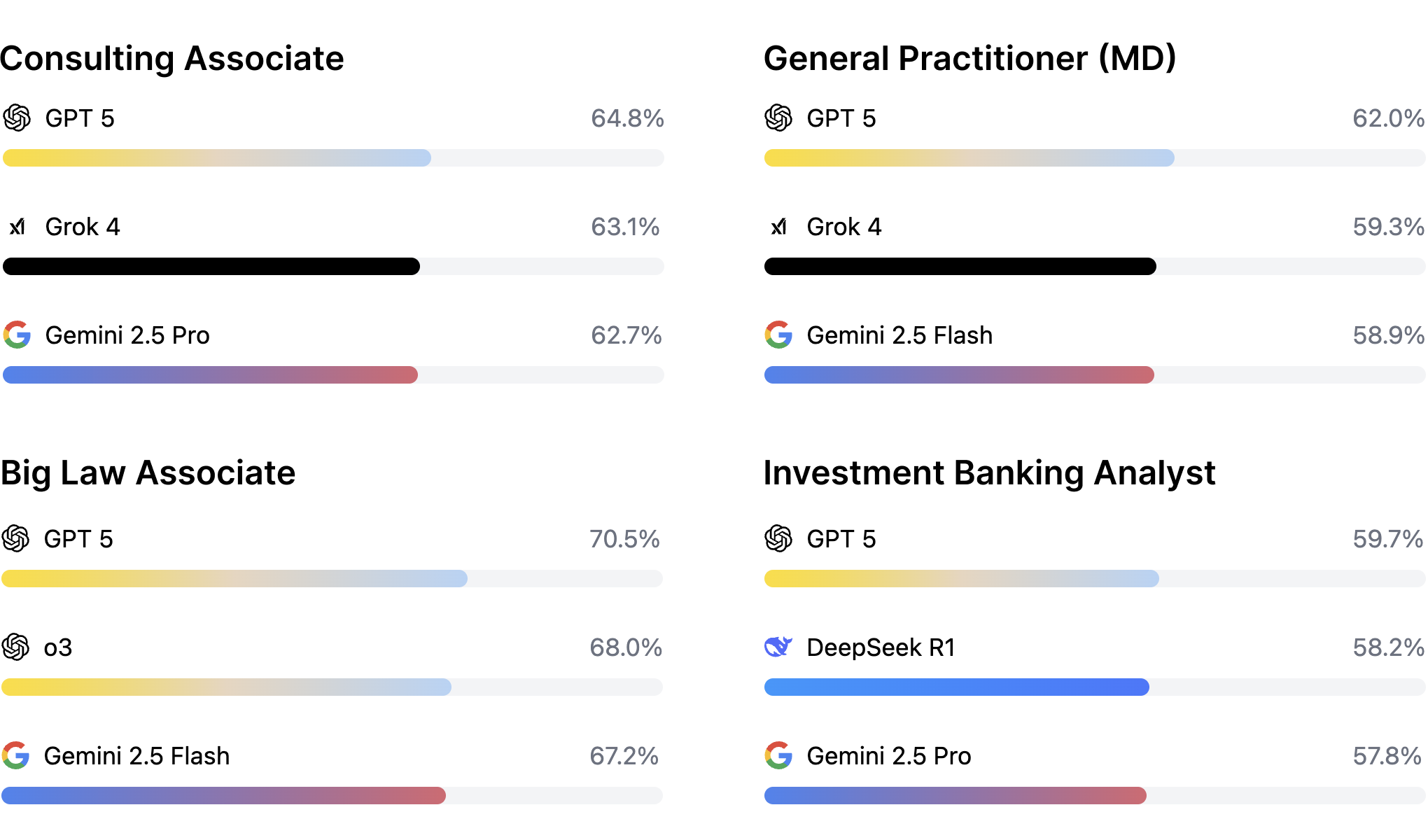
APEX開発の5ステッププロセス
APEXベンチマークの構築には、厳密な5段階プロセスが採用された。各ステップで専門家の知見が活用され、実務との整合性が担保されている。
ステップ1:専門家ソーシング
投資銀行、法律事務所、コンサルティングファーム、医療機関から約100名の専門家を招集。各分野で実際に発生する業務タスクの特定を依頼。
ステップ2:プロンプト生成
専門家が実務経験に基づき、300のタスクプロンプトを作成。品質管理を経て200プロンプトを承認。各プロンプトには以下が含まれる:
- タスク記述:具体的な業務内容と目標
- ソース資料:平均5.83の参照ドキュメント(平均26,000トークン)
- 評価ルーブリック:平均29.09の評価基準
ステップ3:ソース生成
各タスクに必要な情報源を準備。契約書、財務諸表、医療記録、市場レポートなど、実務で使用される実際の文書形式を採用。
ステップ4:ルーブリック作成
専門家が各タスクの評価基準を詳細に定義。Pass/Failの二値評価で明確な採点基準を設定。
ステップ5:品質管理
複数の専門家によるクロスチェックを実施。タスクの妥当性、評価基準の明確性、実務との整合性を検証。
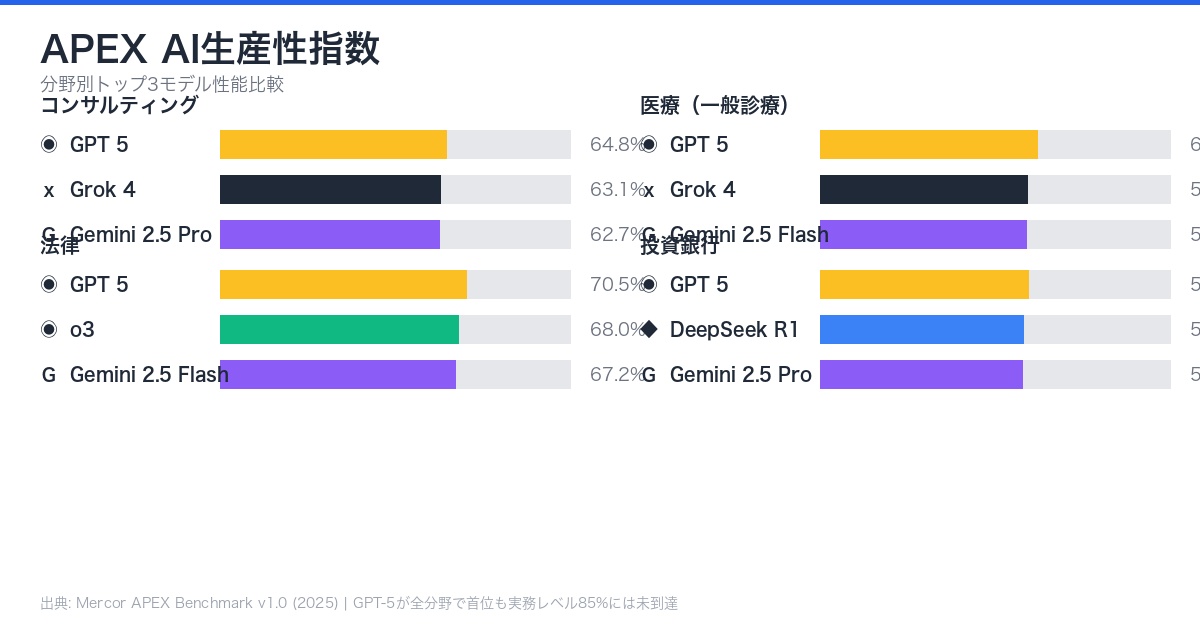
衝撃の評価結果:GPT-5でさえ64.2%
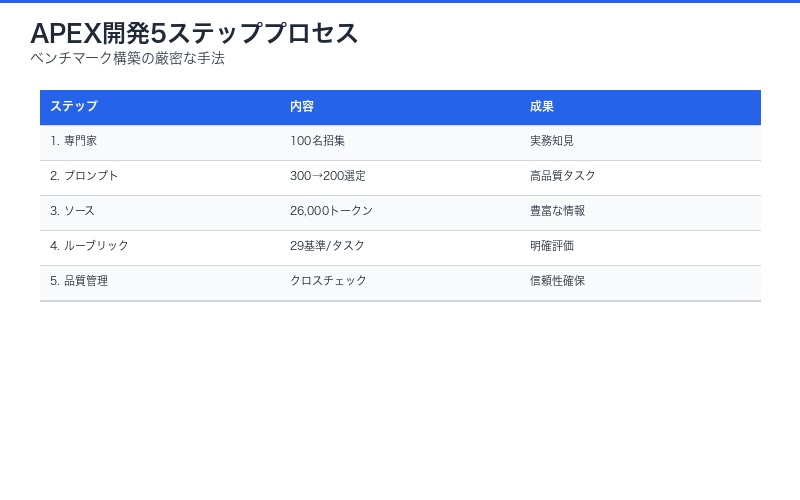
23モデルを評価した結果、最高性能のGPT-5(Thinking = High)でさえ64.2%のスコアに留まった。この数値が意味するのは、評価基準の約3分の1は満たせていないという現実だ。
トップ10モデルのスコア
| 順位 | モデル名 | スコア | 分類 |
|---|---|---|---|
| 1 | GPT-5 (Thinking = High) | 64.2% | クローズド |
| 2 | Claude 3.5 Sonnet (New) | 63.2% | クローズド |
| 3 | Gemini 2.0 Flash Thinking | 62.8% | クローズド |
| 4 | GPT-4.5 Turbo | 61.5% | クローズド |
| 5 | o1 | 60.7% | クローズド |
| 6 | Gemini 2.5 Pro | 60.1% | クローズド |
| 7 | Qwen3 (最高オープンソース) | 59.8% | オープンソース |
| 8 | Claude 3 Opus | 58.9% | クローズド |
| 9 | GPT-4o | 57.3% | クローズド |
| 10 | Llama 3.3 70B | 56.4% | オープンソース |
重要な統計的知見
- クローズドソース平均:55.2%
- オープンソース平均:45.8%(約9.4ポイント差)
- 最高と最低の差:64.2% vs 37.1%(27.1ポイント差)
- 統計的有意性:Kruskal-Wallis検定でα=0.00001で有意差を確認
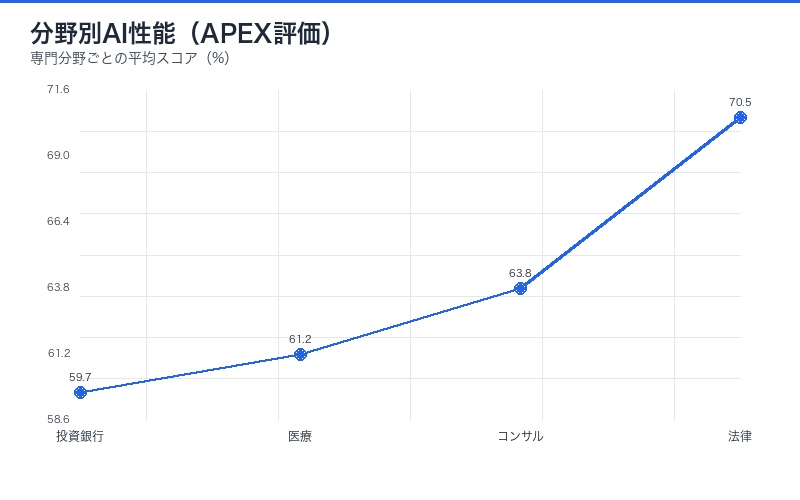
分野別性能:法律が最高、投資銀行が最低
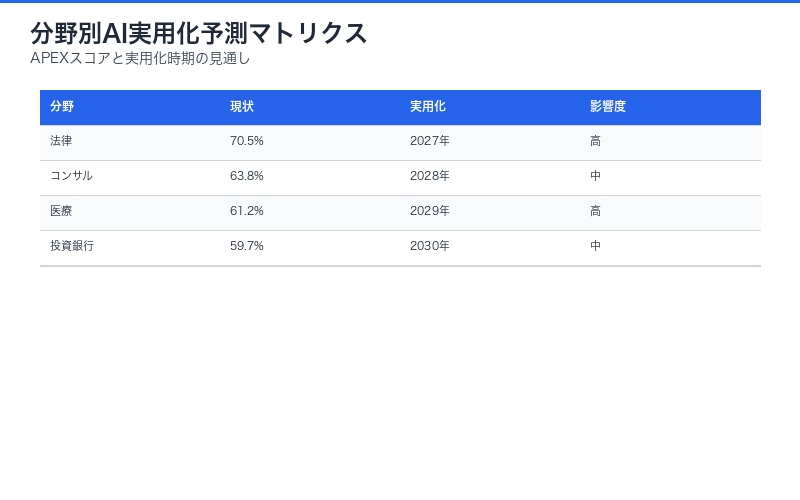
4つの専門分野で顕著な性能差が観察された。法律分野で最も高い70.5%、投資銀行で最も低い59.7%という結果は、タスクの性質とAIの得意不得意を如実に示している。
分野別平均スコア
| 分野 | 平均スコア | 特徴 |
|---|---|---|
| 法律 | 70.5% | 文書分析、判例検索が中心 |
| コンサルティング | 63.8% | 戦略立案、データ分析 |
| 医療 | 61.2% | 診断支援、カルテ分析 |
| 投資銀行 | 59.7% | 財務モデリング、取引分析 |
なぜ法律が最も高く、投資銀行が最も低いのか
法律分野の優位性は、以下の要因による:
- 構造化された情報:判例、法律条文は明確に構造化されている
- パターン認識:類似ケースの検索はLLMの得意分野
- 文章生成:契約書ドラフトなど、テンプレートベースの作業が多い
投資銀行の課題は、以下に起因する:
- 高度な数値分析:複雑な財務モデリングが必要
- 市場感覚:定量データだけでは判断できない要素が多い
- リスク評価:不確実性への対応が求められる
評価手法の革新性:LMジャッジによる客観的評価
APEXの評価には、3つのLM(Language Model)ジャッジによるパネル方式が採用されている。人間の評価者に依存する従来手法と比べ、以下の利点がある:
LMジャッジの評価プロセス
- 3回の回答生成:各タスクに対して同一モデルが3回回答を生成
- パネル評価:3つのLMジャッジが各回答を独立に評価
- 基準別採点:29個の基準それぞれをPass/Failで判定
- 多数決方式:3ジャッジのうち2つ以上がPassなら合格
- 中央値スコア:3回の回答のうち中央値をリーダーボードに採用
評価の信頼性
統計分析により、以下が確認された:
- OLS回帰分析:モデル名だけで分散の22.8%を説明可能
- 統計的有意差:モデル間の性能差は偶然ではない(p
- 再現性:同一モデルの3回評価で一貫性を確認
評価手法の限界:
研究チームは以下の限界を認めている:
- 誤った主張に対する減点がない
- 測定誤差の可能性
- 経済的価値との直接的相関は未検証
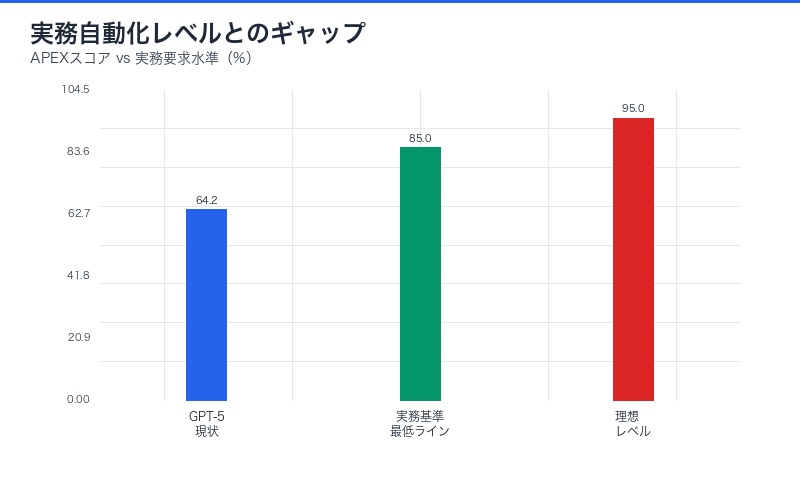
「実務レベルに未到達」が意味すること
APEXが示した最も衝撃的な結論は、「どのモデルも実務タスクの自動化基準を満たしていない」というものだ。これは何を意味するのか。
実務自動化の基準とは
Mercor研究チームによれば、実務タスクを自動化できるAIには以下が求められる:
| 要件 | 現状 | ギャップ |
|---|---|---|
| 精度 | 64.2%(最高) | 85-95%が必要 |
| 一貫性 | タスク間でばらつき大 | 安定性の向上が必須 |
| 信頼性 | 誤りへの対処なし | ファクトチェック機構 |
| 説明可能性 | 不透明 | 意思決定プロセスの可視化 |
64.2%スコアの現実的意味
投資銀行のM&A分析を例に取ると:
- 合格基準29個のうち約10個は不合格
- 不合格項目は予測不可能:どの基準で失敗するか不明
- 人間のレビュー必須:結果的に自動化の意味が薄れる
- リスクが高すぎる:重要な意思決定には使えない
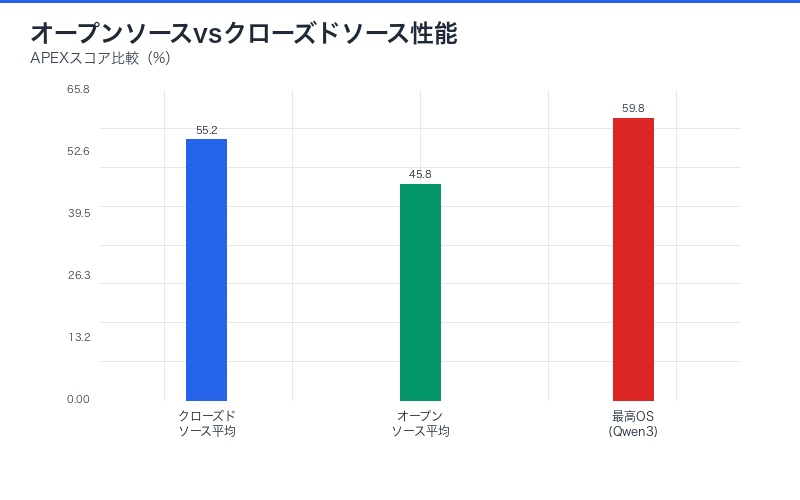
クローズドソースとオープンソースの9.4ポイント差
APEXは、クローズドソースモデル(55.2%)とオープンソースモデル(45.8%)の間に9.4ポイントの差があることを明らかにした。この差は、AI開発における重要なトレンドを示唆している。
最高オープンソースモデルの位置づけ
Qwen3が59.8%で7位にランクイン。これは:
- OpenAI GPT-4o(57.3%)を上回る:オープンソースの急速な進化
- トップとは4.4ポイント差:まだ差はあるが縮小傾向
- 実用性の証明:適切なチューニングで実務に使える可能性
なぜクローズドソースが優位なのか
| 要因 | クローズドソースの優位性 |
|---|---|
| 計算リソース | 莫大な学習予算(数百億円規模) |
| データ品質 | 高品質な独自データセット |
| RLHF | 大規模な人間フィードバック |
| 継続的改善 | 実運用データでの継続的学習 |
APEXが示すAIエージェントの未来
APEXの結果は、AIエージェントブームに重要な示唆を与える。「AIが仕事を奪う」という議論は時期尚早であり、より現実的なアプローチが必要だ。
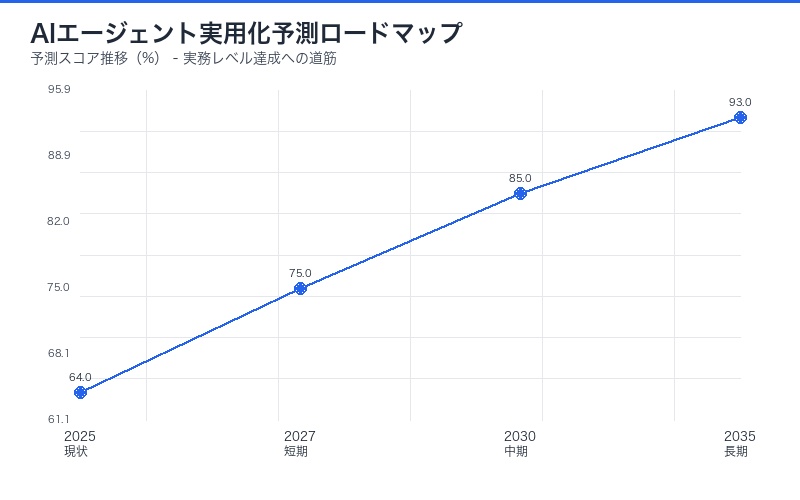
短期的展望(1-2年)
- AI補助ツール:完全自動化ではなく、人間の作業を支援
- 特定タスクの自動化:文書要約、データ抽出など限定的なタスク
- 品質管理の重要性:人間によるレビュープロセスは必須
中期的展望(3-5年)
- ハイブリッド型ワークフロー:AIと人間の協働が標準に
- 専門特化モデル:分野別にファインチューニングされたモデル
- 信頼性向上:85%以上のスコアを目指す技術開発
長期的展望(5年以上)
- 完全自動化の一部実現:リスクの低いタスクから段階的に
- 新しい職種の創出:AIマネージャー、品質管理専門家など
- 経済構造の変化:生産性向上による産業構造の転換
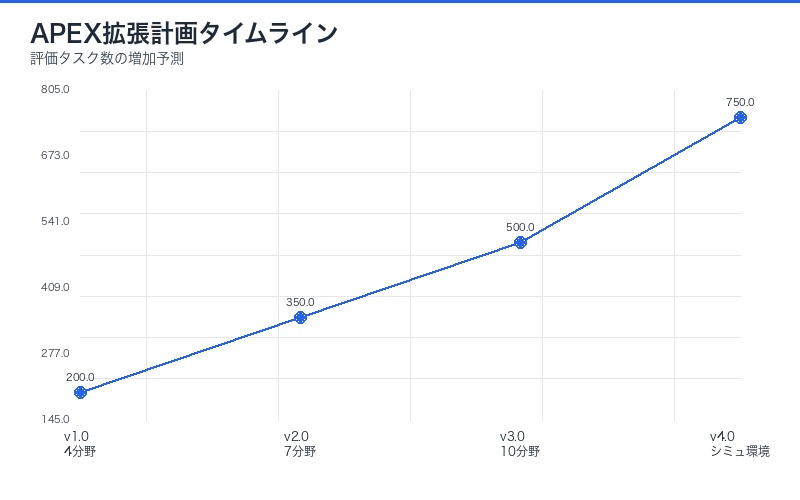
Mercorの今後の展開:シミュレーション環境の導入
Mercor研究チームは、APEXの今後の展開として以下を計画している:
1. シミュレーション環境の構築
現在のAPEXは単一タスクの評価に留まるが、今後は:
- マルチステップタスク:複数のタスクを連続実行
- 環境との相互作用:ツール使用、データベースアクセス
- 長期プロジェクト:数日〜数週間かかる業務の自動化
2. 対象分野の拡大
現在の4分野から、以下への拡大を計画:
- 会計・監査
- エンジニアリング
- マーケティング・広告
- 教育
- カスタマーサポート
3. 不完全なAIモデルの経済的影響研究
64%の精度でも、以下の経済的価値がある可能性:
- 作業時間短縮:ドラフト生成で50-70%の時間削減
- アイデア創出支援:ブレインストーミングの効率化
- エラー検出:人間のミスを指摘する補助的役割
研究チームからのメッセージ:
「APEXは終点ではなく、始点である。AIの経済的価値を正確に測定し、実務での適用可能性を科学的に評価する旅の第一歩だ。不完全なAIでも、適切に活用すれば大きな価値を生み出せる。」
– apex@mercor.com
業界への影響:AI開発企業はどう対応すべきか
APEXの発表は、AI開発企業に以下の課題を突きつけている:
OpenAI・Anthropic・Googleへの影響
| 企業 | 現状スコア | 必要な改善 |
|---|---|---|
| OpenAI | GPT-5: 64.2% | 精度向上20-30ポイント |
| Anthropic | Claude 3.5: 63.2% | 一貫性の改善 |
| Gemini 2.0: 62.8% | 複雑タスク対応力強化 |
オープンソースコミュニティへの示唆
Qwen3の7位ランクインは希望的だが、以下の課題が残る:
- リソース格差:学習コストでクローズドソースに劣る
- データアクセス:高品質な学習データの入手困難
- 評価インフラ:継続的な性能測定の仕組み不足
企業ユーザーへの提言
APEXの結果を踏まえ、AIを導入する企業は:
- 過度な期待を持たない:完全自動化は当面困難
- 段階的導入:リスクの低いタスクから試験運用
- 品質管理体制:人間によるレビュー体制の構築
- ROI測定:経済的効果を定量的に評価
- 継続的モニタリング:性能の定期的な再評価
日本企業への影響と対応策
日本の専門サービス業界にとって、APEXは重要な意味を持つ。
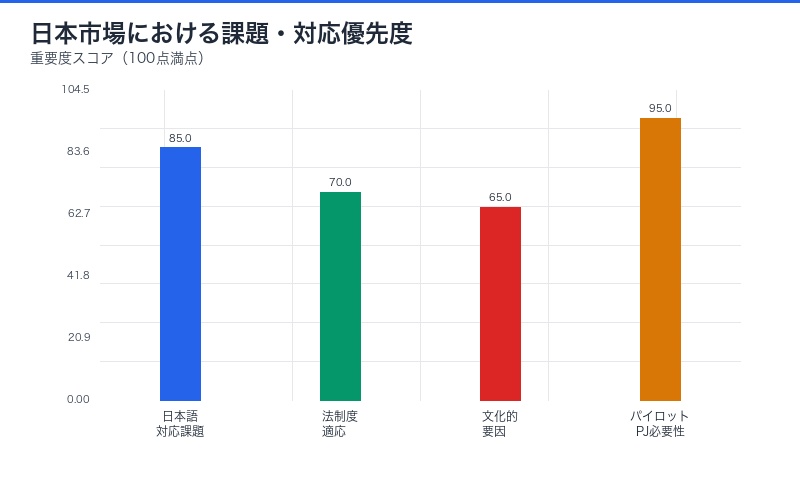
日本市場特有の課題
- 日本語対応:APEXは英語ベース、日本語での性能は不明
- 法制度の違い:日本の法律・医療システムへの適応性
- 文化的要因:日本的な業務プロセスとの整合性
日本企業の取るべきアクション
| アクション | 優先度 | 期待効果 |
|---|---|---|
| 日本語版APEXの開発 | 高 | 国内モデルの客観評価 |
| パイロットプロジェクト | 高 | 実務適用可能性の検証 |
| 人材育成 | 中 | AIリテラシー向上 |
| 業界団体での議論 | 中 | 倫理基準・品質基準の策定 |
まとめ:APEXが切り開くAI評価の新時代
MercorのAPEX AI Productivity Indexは、AI評価のパラダイムシフトを象徴している。学術的能力ではなく経済的価値創出能力を測定するという新しいアプローチは、AI開発の方向性を大きく変える可能性がある。
重要なポイント
- 現実の厳しさ:最高のGPT-5でさえ64.2%、実務レベルには未到達
- 分野差の大きさ:法律70.5% vs 投資銀行59.7%、タスク特性が重要
- オープンソースの健闘:Qwen3が7位、トップとの差は縮小傾向
- 評価手法の革新:LMジャッジによる客観的・再現可能な評価
- 未来への道筋:シミュレーション環境、分野拡大の計画
今後の展望
APEXは以下の方向性を示唆している:
- 短期(1-2年):AI補助ツールとしての活用、特定タスクの部分自動化
- 中期(3-5年):85%以上のスコア達成、ハイブリッド型ワークフローの標準化
- 長期(5年以上):完全自動化の部分的実現、新しい職種の創出
結論:
APEXは「AIが仕事を奪う」という単純な議論を超えて、「AIがどのように経済的価値を生み出せるか」という本質的な問いを投げかけている。64.2%という数字は、AIの可能性と限界の両方を示す。重要なのは、この現実を直視し、適切な期待値を持ちながら、AIと人間の協働による生産性向上を目指すことだ。
Mercor研究チームへの問い合わせ:apex@mercor.com
論文詳細:arXiv:2509.25721v1
コメント