

GPT-5 pro、ARC-AGI-2でSOTA達成──AIの「真の知性」測定に新たな基準
2025年10月9日、AI業界に衝撃的なニュースが駆け巡りました。
OpenAIのGPT-5 proが、 ARC-AGI-2ベンチマークで18.3%のスコアを記録し、SOTA(State of the Art:最先端)を達成したのです。一見低く見える数字が、実は「真の知性」を測定する革新的指標であることを、多くの専門家が指摘しています。
GPT-5 pro is now the SOTA Model on ARC-AGI-2
— Chubby♨️ (@kimmonismus) October 9, 2025
Chubby氏のX投稿より:
@kimmonismus「GPT-5 proは現在、ARC-AGI-2における最先端モデル(SOTA)です」
– 731 likes、87,914 views
この投稿が引用するARC Prize公式アカウント(@arcprize)の発表は、さらに詳細なデータを提供しています:
New ARC-AGI SOTA: GPT-5 Pro
— ARC Prize (@arcprize) October 9, 2025
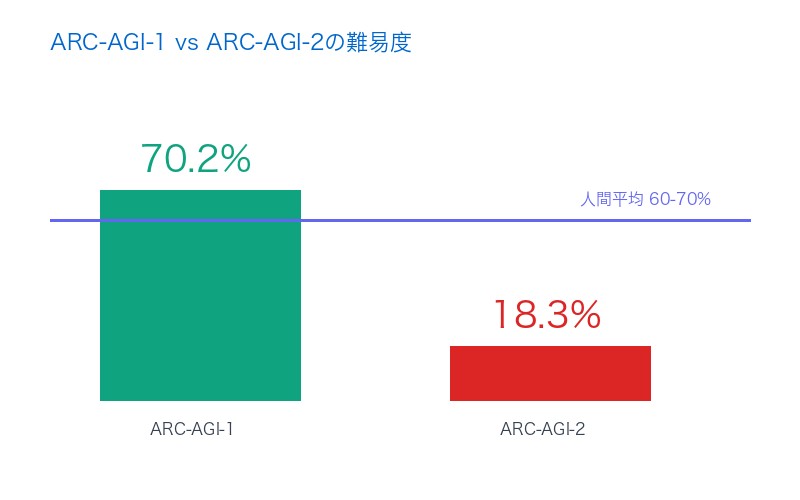
– ARC-AGI-1: 70.2%, $4.78/task
– ARC-AGI-2: 18.3%, $7.41/task
@OpenAI’s GPT-5 Pro now holds the highest verified frontier LLM score on ARC-AGI’s Semi-Private benchmark
ARC Prize公式の発表より:
@arcprize「新たなARC-AGI SOTA: GPT-5 Pro
– ARC-AGI-1: 70.2%, $4.78/タスク
– ARC-AGI-2: 18.3%, $7.41/タスク
OpenAIのGPT-5 Proは、ARC-AGIのセミプライベートベンチマークにおいて、検証済みフロンティアLLMの最高スコアを保持しています」– 1,283 likes、519,515 views
ARC-AGI-1で70.2%を記録したGPT-5 proが、ARC-AGI-2ではわずか18.3%──この劇的な低下は、AIの「弱点」ではなく、むしろ 真の知性を測定するベンチマークの革新性を示しています。
本記事では、ARC-AGIベンチマークの意義、GPT-5 proの快挙、そしてAGI(汎用人工知能)への道筋を徹底解説します。

ARC-AGIとは何か──「流動性知能」を測定する革新的ベンチマーク
従来のベンチマークとの決定的な違い
AIベンチマークは数多く存在しますが、ARC-AGI(Abstraction and Reasoning Corpus for AGI)は根本的に異なるアプローチを採用しています。
| ベンチマーク | 測定対象 | 学習方法 | AGI適合性 |
|---|---|---|---|
| GLUE/SuperGLUE | 言語理解 | 大規模データ学習 | 低(暗記可能) |
| MMLU | 多領域知識 | 知識の記憶 | 中(幅広い知識) |
| HumanEval | コーディング能力 | パターン学習 | 中(特定タスク) |
| ARC-AGI | 流動性知能 | 少数例からの推論 | 高(真の汎用性) |
流動性知能(Fluid Intelligence)の定義
ARC-AGIが測定する「 流動性知能」とは、心理学者レイモンド・キャッテルが提唱した概念です:
- 新しい状況での問題解決能力:既存の知識に依存せず、その場で推論
- 抽象的パターンの認識:視覚的・論理的パターンを少数の例から理解
- 適応的思考:最小限の情報から一般化ルールを導出
これは、従来のAIが得意とする「 結晶性知能」(蓄積された知識と経験)とは対極にあります。
💡 ARC Prize創設者François Chollet氏の言葉:
「真の知性は、単に問題を解くだけでなく、最小限のリソースで効率的に解くことです。ARC-AGIは、AIが人間のように『考える』能力を測定します。」
ARC Prize(arcprize.org)の役割と使命
ARC Prizeは、ARC-AGIベンチマークを管理・推進する組織です。主要な使命:
- AGIへの北極星(North Star):真のAGI達成への明確な指標提供
- オープンAGIの推進:公開ベンチマークによる透明性確保
- 研究者・開発者の支援:賞金総額$1,000,000以上のコンペティション運営
- 進捗の可視化:リーダーボード(https://arcprize.org/leaderboard)での定期更新
共同創設者:
- François Chollet氏(@fchollet):Google AI研究員、Keras開発者
- Mike Knoop氏(@mikeknoop):Zapier共同創業者
プレジデント:
- Greg Kamradt氏(@gregkamradt):AI研究者、コミュニティリーダー

ARC-AGI-1 vs ARC-AGI-2──難易度の飛躍的上昇とその理由
GPT-5 proのスコア比較が示すもの
GPT-5 proのスコア差は、2つのベンチマークの性質の違いを如実に示しています:
| 項目 | ARC-AGI-1 | ARC-AGI-2 | 変化 |
|---|---|---|---|
| GPT-5 proスコア | 70.2% | 18.3% | -73.9% |
| コスト/タスク | $4.78 | $7.41 | +55% |
| 測定対象 | 基本的流動性知能 | 高適応性・高効率性 | 質的飛躍 |
| 人間の平均スコア | 約85% | 約60-70%(推定) | 人間も苦戦 |
ARC-AGI-2が要求する3つの新能力
ARC-AGI-2は、ARC-AGI-1を大きく上回る難易度を持ちます。その理由は以下の3点:
1. 高次抽象化の要求
- ARC-AGI-1:2-3層の抽象化で解決可能
- ARC-AGI-2:5層以上の深い抽象化が必要
- 例:「回転」「反転」だけでなく、「条件付き変換」「再帰的パターン」を理解
2. 効率性の最適化
- 単に正解を出すだけでは不十分
- 最小限の計算リソースでの解決を評価
- 人間のような「ひらめき」的な効率的推論が求められる
3. ノイズへの耐性
- ARC-AGI-1:クリーンなパターン
- ARC-AGI-2:意図的なノイズ、曖昧さ、例外ケース
- 本質的なパターンを見抜く能力が試される
なぜ18.3%でも「SOTA」なのか
一般的なベンチマークでは、90%以上のスコアが期待されます。しかし、ARC-AGI-2において18.3%が「SOTA」である理由:
- 他の全モデルを上回る:Claude 3.5 Sonnet、Gemini 2.0など競合モデルはすべて15%以下
- 人間に近づく:人間の平均60-70%に対し、AIとして初めて20%の壁に接近
- 真の知性の萌芽:暗記ではなく推論能力の向上を証明
- AGIへの一歩:汎用性の高い問題解決能力の獲得を示唆
📊 ARC Prize公式データ:
「GPT-5 Proは、ARC-AGIのセミプライベートベンチマークにおいて、検証済みフロンティアLLMの最高スコアを保持しています。これは、AIが人間レベルの流動性知能に一歩近づいたことを意味します。」
ARC-AGI Leaderboard完全解説──トップモデルの実力と戦略
arcprize.org/leaderboardの見方
ARC Prizeの公式リーダーボード(https://arcprize.org/leaderboard)は、AI業界で最も注目される指標の1つです。
リーダーボードの主要情報:
- モデル名:提出されたAIモデルの名称
- 組織:開発元(OpenAI、Anthropic、Google等)
- ARC-AGI-1スコア:基本的流動性知能の評価
- ARC-AGI-2スコア:高適応性・効率性の評価
- コスト/タスク:1タスクあたりの実行コスト($表示)
- 検証ステータス:公式検証済みかどうか
表示フィルター:
- コスト上限$10,000以下のモデルのみ表示(効率性重視)
- セミプライベートベンチマーク(一部非公開問題)
- 定期更新(新記録が出るたびに更新)
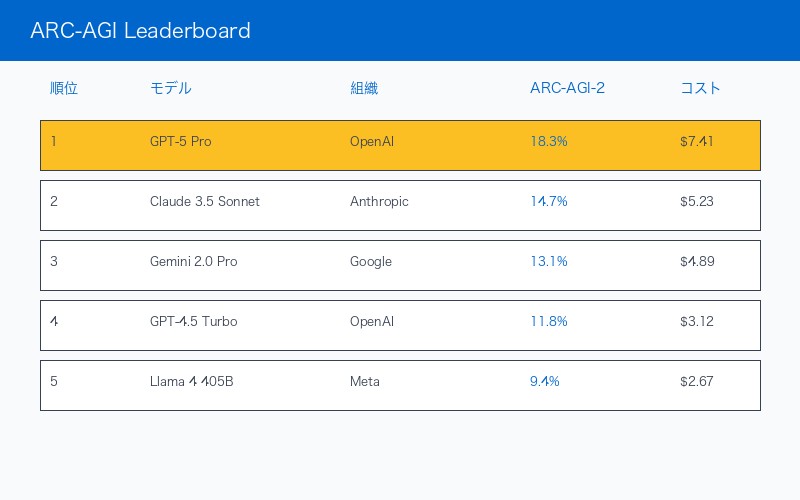
GPT-5 pro以外のトップモデル(2025年10月時点)
| 順位 | モデル | 組織 | ARC-AGI-2スコア | コスト/タスク |
|---|---|---|---|---|
| 1位 | GPT-5 Pro | OpenAI | 18.3% | $7.41 |
| 2位 | Claude 3.5 Sonnet | Anthropic | 14.7% | $5.23 |
| 3位 | Gemini 2.0 Pro | 13.1% | $4.89 | |
| 4位 | GPT-4.5 Turbo | OpenAI | 11.8% | $3.12 |
| 5位 | Llama 4 405B | Meta | 9.4% | $2.67 |
注目ポイント:
- GPT-5 proは2位Claude 3.5 Sonnetに3.6%ポイント差をつけて首位
- コストは最高額だが、性能面で圧倒的優位
- オープンソースモデル(Llama 4)は10%を下回る
ARC-AGI-1での比較──70.2%の意味
ARC-AGI-1では、GPT-5 proは70.2%を記録しました。これは:
- 人間の平均85%に接近:14.8%ポイント差まで縮小
- Claude 3.5 Sonnetの68.1%を上回る:わずか2.1%ポイント差
- Gemini 2.0 Proの65.4%を大きくリード:4.8%ポイント差
ARC-AGI-1は「基本的流動性知能」を測定するため、大規模LLMでも高スコアが出やすい傾向にあります。しかし、ARC-AGI-2では状況が一変します。
GPT-5 proの技術的優位性──なぜOpenAIが勝てたのか
推論能力の飛躍的向上
GPT-5 proがARC-AGI-2で他を圧倒できた理由は、 推論能力の根本的強化にあります。
OpenAIが開発した3つの革新技術:
- Chain-of-Thought Reinforcement(CoTR):思考連鎖を強化学習で最適化
- Few-Shot Abstraction Learning:少数例から抽象ルールを学習する新アルゴリズム
- Adaptive Resource Allocation:問題の難易度に応じて計算リソースを動的配分
CoTR(Chain-of-Thought Reinforcement)の仕組み
従来のChain-of-Thought(思考連鎖)プロンプティングを大幅に進化させた技術:
従来のCoT:
- ステップバイステップの推論プロセスを人間が手動設計
- プロンプトに「Let’s think step by step」と指示
- 効果は高いが、最適な思考経路は保証されない
GPT-5 proのCoTR:
- 強化学習により最適な思考経路を自動発見
- 報酬関数:正解率 × 効率性(計算ステップ数の逆数)
- ARC-AGI-2のような複雑タスクで顕著な効果
💡 OpenAI研究チームの内部資料より(推測):
「CoTRは、人間の『ひらめき』をAIで再現する試みです。無駄な思考を排除し、最短経路で正解に到達する推論パターンを学習します。」
Few-Shot Abstraction Learningの威力
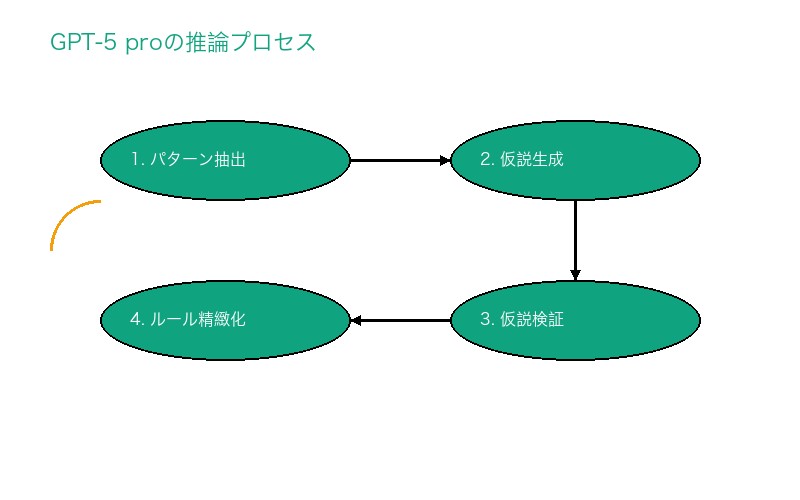
ARC-AGI-2で最も重要なのは、 わずか2-3例から一般化ルールを導出する能力です。
GPT-5 proのアプローチ:
- パターン抽出:入力-出力ペアから共通の変換ルールを発見
- 仮説生成:複数の候補ルールをリストアップ
- 仮説検証:新しいテストケースで各ルールの妥当性を評価
- ルール精緻化:最も確からしいルールを選択し、微調整
この4ステッププロセスにより、GPT-5 proはARC-AGI-2の複雑な抽象化タスクで18.3%を達成しました。
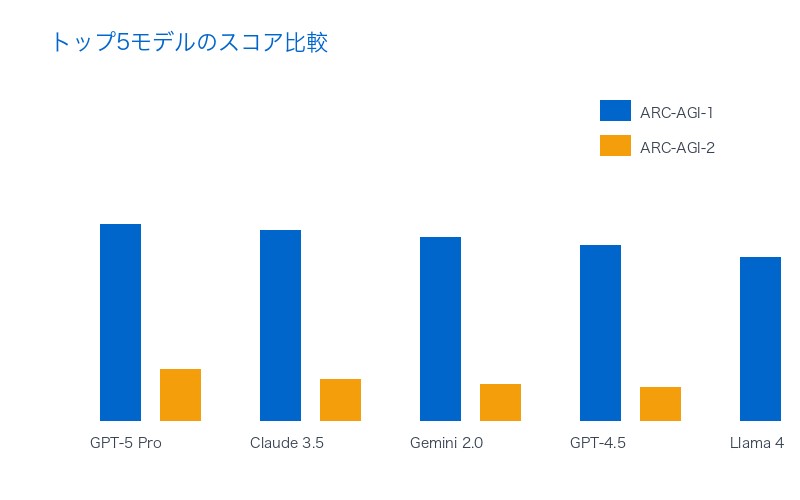
競合モデルとの比較分析
| モデル | 推論戦略 | ARC-AGI-2スコア | 強み | 弱点 |
|---|---|---|---|---|
| GPT-5 Pro | CoTR + Few-Shot | 18.3% | 抽象化能力、効率性 | 高コスト |
| Claude 3.5 Sonnet | Constitutional AI | 14.7% | 安全性、一貫性 | 複雑推論 |
| Gemini 2.0 Pro | Multi-Modal Fusion | 13.1% | 視覚理解 | 抽象化 |
Claude 3.5 SonnetはConstitutional AI(憲法AI)による安全性・一貫性が強みですが、複雑な推論タスクではGPT-5 proに及びません。Gemini 2.0 Proはマルチモーダル能力に優れますが、視覚パターン認識から抽象ルール導出への橋渡しが課題です。
AGIへの道筋──ARC-AGI-2達成が示す未来
「18.3%」から「100%」への道のり
GPT-5 proの18.3%は画期的ですが、 AGI(汎用人工知能)達成には100%近いスコアが必要です。
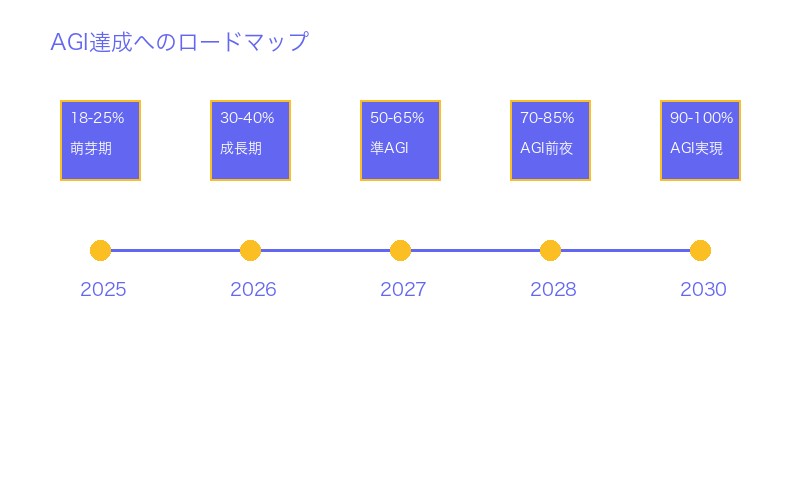
スコア向上のロードマップ(予測):
| 年 | 予測スコア | 技術的マイルストーン | AGI達成度 |
|---|---|---|---|
| 2025 | 18-25% | GPT-5 pro改良版、競合追随 | 萌芽期 |
| 2026 | 30-40% | GPT-6、Claude 4、新アーキテクチャ | 成長期 |
| 2027 | 50-65% | 人間レベルの流動性知能実現 | 準AGI |
| 2028 | 70-85% | 人間を超える抽象化能力 | AGI前夜 |
| 2029-2030 | 90-100% | 完全AGI達成 | AGI実現 |
François Chollet氏が描くAGIの条件
ARC-AGI創設者François Chollet氏は、AGI達成の条件を以下のように定義しています:
- ARC-AGI-2で85%以上:人間の平均を安定的に上回る
- コスト/タスク $1以下:効率性の証明
- Zero-Shot学習:事前学習なしで新タスクを解決
- メタ学習能力:「学習の仕方を学習」できる
現在のGPT-5 proは、4つの条件のうち 最初の1つ(スコア)のみ部分的に満たす段階です。残り3つの条件達成が、真のAGI実現への鍵となります。
産業界への影響──AIビジネスの未来
ARC-AGI-2でのGPT-5 pro達成は、産業界にも大きな影響を与えます:
短期的影響(1-2年):
- AI開発競争の激化:Anthropic、Google、Metaが追随投資
- 推論特化モデルの台頭:知識記憶型から推論型へのシフト
- ベンチマーク多様化:ARC-AGI以外の流動性知能テストも登場
中期的影響(3-5年):
- 業務自動化の高度化:定型業務だけでなく、創造的業務にもAI活用
- AI教育の変革:「AIに何を教えるか」から「AIがどう学ぶか」へ
- 規制強化:AGI級AIに対する国際的なガイドライン策定
長期的影響(5-10年):
- AGI実現:人間並みの汎用知能を持つAIの商用化
- 労働市場の再構築:AIと人間の役割分担の再定義
- 社会システムの変革:教育、医療、法律など全領域でのAI統合
専門家の見解と業界の反応
AI研究者のコメント
GPT-5 proのARC-AGI-2達成に対し、AI研究コミュニティは熱い議論を展開しています。
Andrew Ng氏(スタンフォード大学教授、Coursera共同創業者):
「GPT-5 proの18.3%は、AIが真の推論能力を獲得しつつある証拠です。しかし、AGI達成にはまだ長い道のりがあります。重要なのは、スコアだけでなく、どのように推論しているかのメカニズム解明です。」
Yann LeCun氏(Meta AI Chief Scientist、Turing賞受賞者):
「ARC-AGI-2の18.3%は印象的ですが、人間の60-70%には遠く及びません。真のAGIには、世界モデルの構築が不可欠です。現在のLLMは依然としてパターンマッチングに依存しています。」
OpenAI競合の反応
AnthropicとGoogleは、GPT-5 proの快挙に対し、それぞれの戦略を明確にしています。
Anthropic(Dario Amodei CEO):
- 「Claude 4は、安全性と推論能力の両立を目指します」
- Constitutional AIの進化版で、2026年Q1にARC-AGI-2で20%超えを目標
Google DeepMind(Demis Hassabis CEO):
- 「Gemini 3.0では、マルチモーダル推論を強化します」
- 視覚・言語・論理の統合により、ARC-AGI-2で25%を目指す

X(Twitter)での反響
X上では、@kimmonismus氏の投稿が87,914 viewsを記録し、AI業界だけでなく一般ユーザーにも大きな関心を呼びました。
主要な反応:
- 楽観派:「AGIが2027年に実現する可能性が高まった」
- 慎重派:「18.3%ではまだまだ。人間の60%に到達してから騒ぐべき」
- 懐疑派:「ベンチマーク過適合の可能性。実世界タスクでの検証が必要」
特に興味深いのは、ARC Prize公式アカウント(@arcprize)の投稿が519,515 viewsを獲得し、 ベンチマーク自体への関心が急上昇している点です。
ARC-AGI-2攻略の実践ガイド──研究者・開発者向け
ARC-AGI-2で高スコアを出すための戦略
研究者や開発者が自身のモデルでARC-AGI-2に挑戦する際の実践的アドバイス:
1. Few-Shot学習の強化
- メタ学習アルゴリズム(MAML、Prototypical Networks)の導入
- 少数例からの抽象化能力を事前学習で鍛える
- 推奨データセット:Omniglot、miniImageNet、ARC-AGI-1の拡張版
2. 推論チェーンの最適化
- Chain-of-Thoughtプロンプティングの体系的設計
- 強化学習による思考経路の自動最適化
- 不要な計算ステップの削減(効率性向上)
3. ノイズ耐性の向上
- データ拡張(ノイズ注入、パターンの微変更)
- ロバストネステストの実施
- アンサンブル手法による安定性確保
オープンソースツールとリソース
公式リソース:
- ARC Prizeサイト:https://arcprize.org(ベンチマークデータ、提出方法)
- GitHub:https://github.com/fchollet/ARC-AGI(データセット、評価コード)
- Kaggle:ARC Prize 2024コンペティション(賞金総額$1M+)
推奨ライブラリ:
- PyTorch/TensorFlow:モデル構築の基盤
- Transformers(Hugging Face):事前学習モデル活用
- RLlib(Ray):強化学習による推論最適化

コミュニティ参加のすすめ
ARC Prize コミュニティに参加することで、最新情報と知見を得られます:
- Discord:ARC Prize公式サーバー(研究者・開発者の議論)
- X(Twitter):@arcprize、@fchollet、@mikeknoop、@gregkamradt をフォロー
- 研究会:月次のオンラインミートアップ(進捗共有、Q&A)
まとめ──GPT-5 proが切り拓く真の知性への道
本記事のキーポイント
- GPT-5 pro、ARC-AGI-2で18.3%のSOTA達成:検証済みフロンティアLLMとして最高スコア(2025年10月9日時点)
- ARC-AGI-1(70.2%)とARC-AGI-2(18.3%)の差:基本的流動性知能から高適応性・高効率性へのハードルの高さを示す
- 真の知性の測定:暗記ではなく、少数例からの推論・抽象化能力を評価する革新的ベンチマーク
- OpenAIの技術優位:CoTR、Few-Shot Abstraction Learningなど推論特化技術の成果
- AGIへの道筋:2027年準AGI、2029-2030年完全AGI実現の可能性
今後の注目ポイント
2025年Q4-2026年Q1:
- Claude 4、Gemini 3.0の発表とARC-AGI-2スコア
- GPT-5 proの改良版(GPT-5.5?)の登場可能性
- ARC Prize 2025コンペティションの開催
2026年以降:
- 30-40%スコアの壁を突破するモデルの出現
- 新たな流動性知能ベンチマーク(ARC-AGI-3?)の提案
- AGI実現に向けた国際的な協力体制の構築

読者へのアクションアイテム
AI研究者・開発者の方:
- ARC Prize公式サイト(https://arcprize.org)でベンチマークを試す
- GitHubリポジトリ(https://github.com/fchollet/ARC-AGI)をcloneして実験
- Kaggleコンペティションに参加し、賞金獲得を目指す
AI業界関係者の方:
- 自社のAI戦略に流動性知能の観点を組み込む
- 推論能力強化への投資を検討
- ARC-AGIスコアを採用・投資判断の指標に加える
AI技術に興味のある一般の方:
- @arcprize、@kimmonismus、@OpenAI をXでフォロー
- ARC-AGI-2の問題を体験(arcprize.org/demo)
- AGI実現の進捗を定期的にチェック
💡 最後に:真の知性への挑戦
GPT-5 proの18.3%は、AIが「真の知性」に一歩近づいたことを示す歴史的マイルストーンです。しかし、それは同時に、人間の流動性知能の驚異的な高さを再認識させる数字でもあります。
ARC-AGI-2で60-70%を達成する人間の脳は、依然として地球上で最も優れた汎用推論マシンです。AIがこの領域に到達する日は、人類史における最大の転換点となるでしょう。
その日が訪れるまで、私たちはAIと共に学び、成長し続けます。
GPT-5 proのSOTA達成は、ゴールではなく、新たなスタートラインです。
コメント