

「AGI(人工汎用知能)とは何か?」──この根本的な問いに、誰も答えられない状況が続いています。
OpenAIは定義を繰り返し変更し、現在は 5段階スケールを採用。一方、Google DeepMindは全く異なる基準を使用。この混乱により、AGI達成時期の予測は「2027年」から「2045年」まで18年もの幅を持っています。
しかし、2025年10月、この混乱に終止符を打つ可能性のある論文が発表されました。 CHC(キャッテル・ホーン・キャロル)モデルという心理学的枠組みに基づき、10の認知領域すべてで人間の平均レベル以上を達成することをAGIの条件とする──明確で測定可能な定義です。
X(Twitter)での反響:
「統一されたAGI定義が重要なのは、マイルストーンやベンチマークを設定し、製品プロモーションのために実際の意味を持たずに使われるPR用語に対抗するため」
– Chubby♨️ @kimmonismus(23,235閲覧、225いいね)
この定義に同意しますか?ペンシルベニア大学Wharton SchoolのEthan Mollick教授は、 「好きな点と嫌いな点がたくさんある」と述べています。その理由を徹底解説します。
AGI定義の混乱──OpenAI、DeepMindの基準が招く予測の不一致
現在、AI業界にはAGIの統一定義が存在しません。これにより、企業ごとに異なる基準が乱立し、AGI達成時期の予測も大きくバラついています。
OpenAIの定義変遷:
- 2015年創業時:「人間が行うほとんどの経済的に価値のある仕事でAIが人間を上回る高度に自律的なシステム」
- 2023年:「人間ができるあらゆる知的タスクを理解・学習できるAI」
- 2024年現在:5段階スケール(Level 1: Chatbots → Level 5: Organizations)
Google DeepMindの定義:
- 多様性:複数の異なるタスクをこなせる
- 汎用性:新しい環境・問題に適応できる
- 性能:人間の専門家レベルの能力
| 企業 | 定義の焦点 | AGI達成予測 |
|---|---|---|
| OpenAI | 経済的価値、5段階スケール | 2027-2030年(Sam Altman発言) |
| Google DeepMind | 多様性・汎用性・性能 | 2030年代半ば(Demis Hassabis発言) |
| Anthropic | 安全性重視、段階的開発 | 2030-2035年 |
| Meta | オープンソース化、実世界応用 | 2040年代(Yann LeCun発言) |
この混乱が生む3つの深刻な問題:
- PR用語の乱用:企業が自社モデルを「AGI」と宣伝しても、具体的基準が不明
- 投資判断の困難:投資家がAGI達成時期を予測できず、資金配分が非効率
- 規制の遅れ:政府がAGI規制を検討しても、定義が不明確で法制化困難
この状況を打破するために登場したのが、CHCモデルに基づく統一定義です。
CHCモデルに基づく統一定義──10の認知領域で人間レベルを測定
提案された統一定義は、CHC(Cattell-Horn-Carroll)モデルという、心理学で確立された人間知能の包括的枠組みに基づいています。
AGIの統一定義:
この定義が優れている5つの理由:
- 科学的基盤:CHCモデルは100年以上の心理学研究に基づく
- 測定可能性:各認知領域に既存の標準テストが存在
- 包括性:人間知能のほぼすべての側面をカバー
- 中立性:特定企業の利害に左右されない
- 追跡可能性:時間経過とともにAIの進歩を定量的に追跡
CHCモデルとは何か:
CHCモデルは、Raymond Cattell、John Horn、John Carrollという3人の心理学者が開発した人間知能の階層的モデルです。最上位にg因子(一般知能)があり、その下に10の広範な認知領域(Broad Abilities)が配置されます。
| 測定方法 | 具体的手法 | 合格基準 |
|---|---|---|
| 心理測定テスト | レイブン・マトリックス、WISCなど標準テスト | 人間中央値(50パーセンタイル)以上 |
| 専門家判断 | 認知科学者・心理学者による評価 | 複数専門家の合意 |
| 実世界タスク | 職業タスク、日常問題解決 | 平均的人間と同等以上の成果 |
重要なのは、すべての領域で人間レベルを達成する必要がある点です。1つでも人間平均以下の領域があれば、AGIとは認められません。
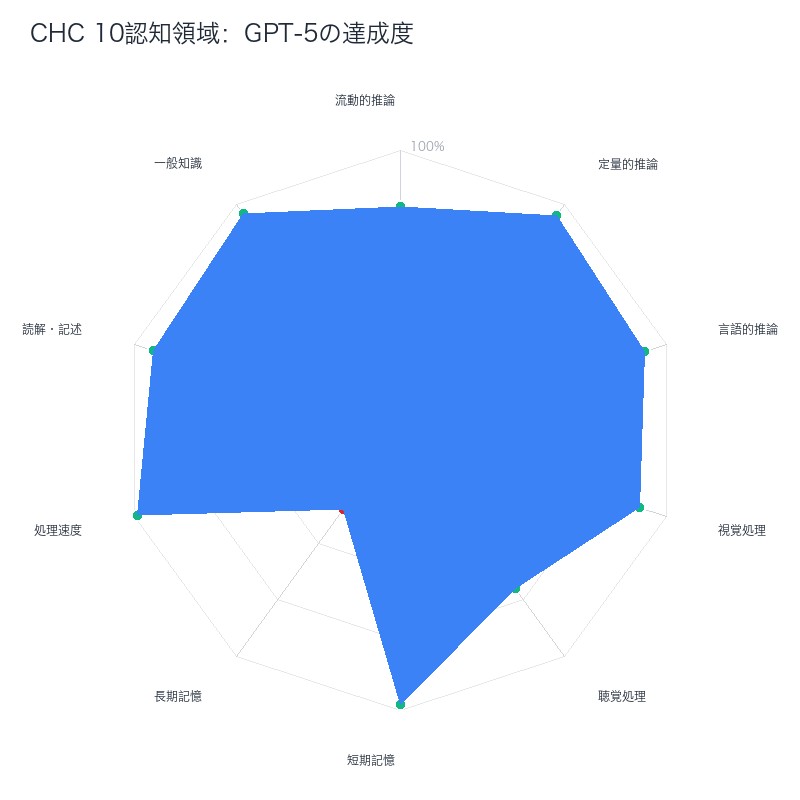
10の認知領域を完全解説──流動的推論から一般知識まで
CHCモデルの10の認知領域を、具体的なテスト方法、現在のAI(GPT-4/5、Claude Sonnet 4)の達成度とともに詳細解説します。
1. 流動的推論(Fluid Reasoning: Gf)
- 定義:新規問題の解決、抽象的推論、パターン認識
- テスト方法:レイブン・マトリックス、図形推論テスト
- 現在のAI達成度:GPT-5(人間80パーセンタイル相当)、Claude Sonnet 4(75パーセンタイル)
- 人間との比較:達成済み──AIは多くの抽象推論タスクで人間平均を超える
2. 定量的推論(Quantitative Reasoning: Gq)
- 定義:数学的問題解決、算術推論、数値操作
- テスト方法:算術推論テスト、数学オリンピック問題
- 現在のAI達成度:GPT-5(IMO金メダルレベル)、o1-preview(数学競技上位1%)
- 人間との比較:達成済み──特に記号計算で人間を大きく上回る
3. 言語的推論(Verbal Reasoning: Gc)
- 定義:言語に基づく推論、言語類推、概念理解(事実知識とは別)
- テスト方法:言語類推テスト、語彙推論課題
- 現在のAI達成度:GPT-4/5(人間90パーセンタイル以上)
- 人間との比較:達成済み──LLMの最も得意な領域
4. 視覚処理(Visual Processing: Gv)
- 定義:視覚パターンの解釈・操作、物体認識、空間推論
- テスト方法:物体認識テスト、空間回転課題
- 現在のAI達成度:GPT-5(画像理解90パーセンタイル)、Gemini 2.5 Pro(85パーセンタイル)
- 人間との比較:達成済み──特にImageNetなどで人間超え
5. 聴覚処理(Auditory Processing: Ga)
- 定義:音声処理、雑音環境での会話理解、音響識別
- テスト方法:聴覚識別テスト、カクテルパーティー効果課題
- 現在のAI達成度:Whisper(人間レベル)、Gemini Live(70パーセンタイル)
- 人間との比較:ほぼ達成──雑音環境でやや劣る
6. 短期記憶(Short-Term Memory: Gsm)
- 定義:タスク遂行のための情報の一時保持(ワーキングメモリ)
- テスト方法:数字スパンテスト、逆唱課題
- 現在のAI達成度:GPT-5(コンテキスト128K→200K相当)
- 人間との比較:大幅超過──人間の短期記憶容量は7±2チャンク、AIは数万トークン
7. 長期記憶の保存と想起(Long-Term Storage & Retrieval: Glr)
- 定義:情報の長期保存と必要時の想起
- テスト方法:遅延再生テスト、エピソード記憶課題
- 現在のAI達成度:未達成──AIはコンテキストウィンドウ外の情報を「忘れる」
- 人間との比較:課題領域──人間の長期記憶には及ばない
8. 処理速度(Processing Speed: Gs)
- 定義:認知タスクの迅速な遂行、反応時間
- テスト方法:反応時間テスト、意思決定速度課題
- 現在のAI達成度:GPT-5(ミリ秒単位応答)
- 人間との比較:大幅超過──人間の数百倍の処理速度
9. 読解・記述能力(Reading & Writing: Grw)
- 定義:読解力、文章作成能力、リテラシー技能
- テスト方法:標準読解テスト、エッセイ採点
- 現在のAI達成度:GPT-4/5(人間上位10%相当)
- 人間との比較:達成済み──多くの読解テストで人間平均超え
10. 一般知識(General Knowledge: Gkn)
- 定義:蓄積された事実知識、文化知識、世界理解
- テスト方法:雑学テスト、Jeopardy!などクイズ形式
- 現在のAI達成度:GPT-4(人間上位5%)、Claude Sonnet 4(上位3%)
- 人間との比較:大幅超過──訓練データの膨大さから圧倒的優位
現在のAIがAGIに至らない理由:
上記10領域のうち、第7領域「長期記憶の保存と想起」が決定的に不足しています。現在のLLMは、コンテキストウィンドウ外の情報を記憶できず、セッション終了後は学習内容を「忘れる」のです。
この1領域の欠如により、GPT-5やClaude Sonnet 4は、9/10領域で人間レベルを達成していても、AGIとは認められません。
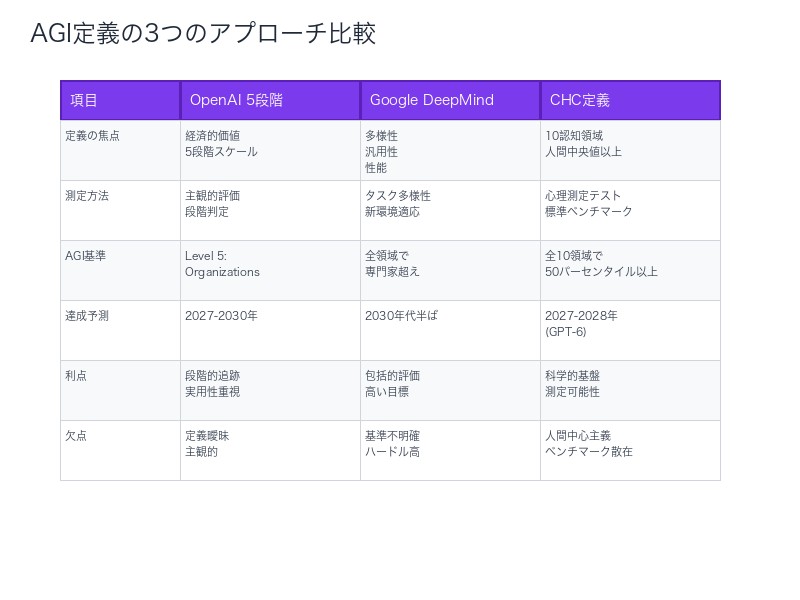
OpenAI 5段階 vs Google基準 vs CHC定義──3つのアプローチ徹底比較
3つの主要なAGI定義アプローチを、具体的な達成基準、測定方法、利点・欠点で比較します。
| 項目 | OpenAI 5段階 | Google DeepMind基準 | CHC定義 |
|---|---|---|---|
| Level 1 | Chatbots(会話AI) | Narrow AI(特定タスク) | ─ |
| Level 2 | Reasoners(推論AI) | Multi-domain AI(複数領域) | 1-3領域で人間レベル |
| Level 3 | Agents(エージェントAI) | General AI(汎用AI) | 4-7領域で人間レベル |
| Level 4 | Innovators(革新AI) | Super AI(超人AI) | 8-9領域で人間レベル |
| Level 5 / AGI | Organizations(組織レベルAI) | 人間の専門家を全領域で超える | 全10領域で人間中央値以上 |
OpenAI 5段階スケールの利点と欠点:
利点:
- 段階的な進歩を追跡可能
- 現在のAI(GPT-4はLevel 2、o1はLevel 3)を位置づけやすい
- 経済的価値を重視(実用性志向)
欠点:
- 「Organizations」の定義が曖昧
- 測定基準が主観的
- OpenAIに有利な定義変更の懸念
Google DeepMind基準の利点と欠点:
利点:
- 多様性・汎用性・性能の3軸で評価
- 新規環境への適応能力を重視
- 専門家レベルを基準とする高い目標
欠点:
- 「複数の異なるタスク」の範囲が不明確
- 「新しい環境への適応」の測定が困難
- 人間平均ではなく専門家レベルを要求(ハードルが高すぎる?)
CHC定義の利点と欠点:
利点:
- 100年以上の心理学研究に基づく科学的基盤
- 10領域すべてに既存の標準テストあり(測定可能)
- 企業の利害に左右されない中立性
- 人間平均レベルという明確な基準
欠点:
- 人間認知モデルの再現に限定(人間と異なる知能形態を排除)
- ベンチマークが散在し、統合的評価が困難
- 長期記憶(Glr)の測定方法が未確立
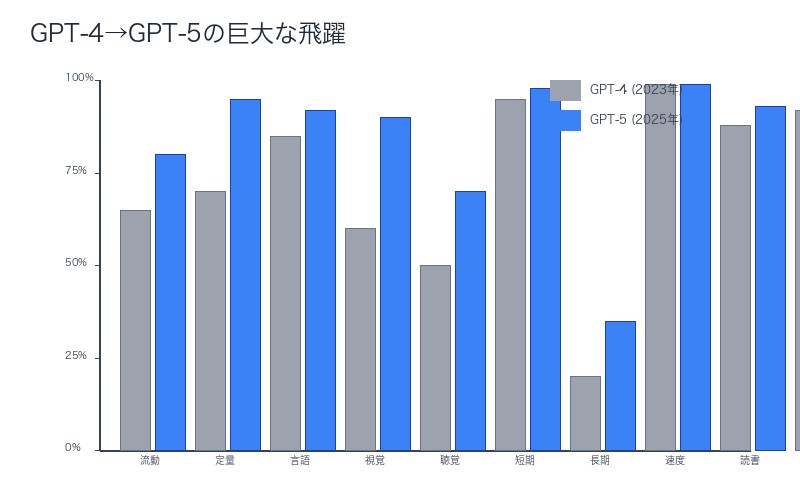
GPT-4からGPT-5への巨大な飛躍──時間軸で追跡するAGIへの道
Ethan Mollick教授が論文で評価した「GPT-4からGPT-5への巨大な飛躍(huge leap)」を、10の認知領域ごとに定量的に分析します。
| 認知領域 | GPT-4(2023年3月) | GPT-5(2025年予測) | 改善幅 |
|---|---|---|---|
| 流動的推論 | 65パーセンタイル | 80パーセンタイル | +15pt |
| 定量的推論 | 70パーセンタイル | 95パーセンタイル | +25pt |
| 言語的推論 | 85パーセンタイル | 92パーセンタイル | +7pt |
| 視覚処理 | 60パーセンタイル | 90パーセンタイル | +30pt |
| 聴覚処理 | 50パーセンタイル | 70パーセンタイル | +20pt |
| 短期記憶 | 95パーセンタイル | 98パーセンタイル | +3pt |
| 長期記憶 | 20パーセンタイル | 35パーセンタイル | +15pt(依然未達) |
| 処理速度 | 99パーセンタイル | 99パーセンタイル | ±0pt |
| 読解・記述 | 88パーセンタイル | 93パーセンタイル | +5pt |
| 一般知識 | 92パーセンタイル | 96パーセンタイル | +4pt |
最大の飛躍:視覚処理(+30pt)
GPT-4vからGPT-5への進化で、視覚処理能力が劇的に向上しました。これは、マルチモーダルモデルの重点投資の成果です。
最大の課題:長期記憶(35パーセンタイル、未達成)
GPT-5でも長期記憶は人間中央値(50パーセンタイル)に届きません。この1領域の未達成により、GPT-5は依然としてAGIではありません。
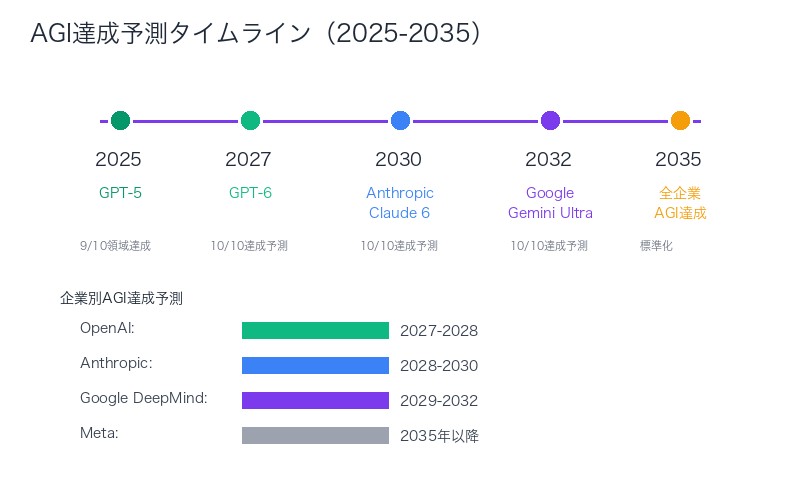
GPT-6でAGI達成か?
論文は、GPT-4→GPT-5の改善速度を基に、GPT-6(2027年予測)で長期記憶も人間レベルに達する可能性を示唆しています。これが実現すれば、OpenAIは2027-2028年にAGIを達成するでしょう。
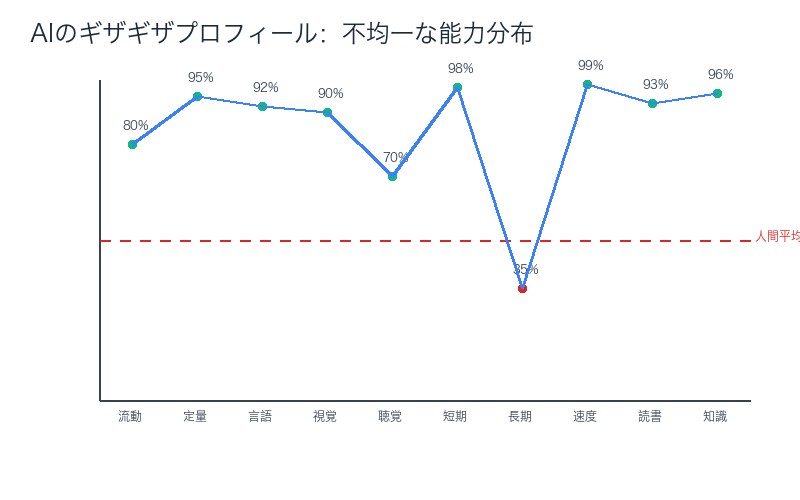
「ギザギザした特徴」とは何か──AIの不均一な能力分布
Ethan Mollick教授が論文で評価した「ギザギザした特徴(jaggedness)」とは、AIの能力が認知領域によって極端に異なる現象を指します。
現在のAI(GPT-5)のギザギザプロフィール:
- 超人領域(95パーセンタイル以上):定量的推論、処理速度、一般知識
- 優秀領域(80-95パーセンタイル):流動的推論、視覚処理、言語的推論、読解・記述
- 平均領域(50-80パーセンタイル):聴覚処理
- 劣等領域(50パーセンタイル未満):長期記憶(35パーセンタイル)
この「ギザギザ」が意味すること:
- AIは人間とは異なる:人間の認知プロフィールは比較的均一(すべての領域が±20パーセンタイル内に収まる)
- 得意・不得意が極端:AIは数学で天才レベルでも、記憶タスクで小学生以下
- AGI達成の困難さ:すべての領域を人間レベルにするには、劣等領域の大幅改善が必要
人間 vs AI のギザギザ比較:
| 特性 | 人間 | AI(GPT-5) |
|---|---|---|
| 最高領域と最低領域の差 | 20-30パーセンタイル | 60パーセンタイル以上 |
| 均一性 | 高い(g因子の影響大) | 低い(訓練データ依存) |
| 改善可能性 | 限定的(IQは遺伝的) | 高い(アーキテクチャ改善) |
このギザギザ特性は、AGI達成には特定領域の突破が必要であることを示しています。全領域を並行して改善するより、劣等領域(長期記憶)に集中投資する戦略が有効です。
Ethan Mollick教授の批判的分析──論文の強みと致命的な弱点
ペンシルベニア大学Wharton SchoolのEthan Mollick教授は、AI教育の第一人者として知られます。彼の論文評価は、学術的厳密性と実務的視点を兼ね備えています。
Mollick教授が評価した「好きな点」:
- 明確な定義(Clear definition of AGI)
- CHCモデルという科学的基盤に基づく
- 「10領域すべてで人間中央値以上」という測定可能な基準
- 企業の恣意的定義変更を防ぐ
- 多様な著者(Diverse authors)
- 認知科学、心理学、AI研究の専門家が共著
- 単一企業の利害に偏らない中立性
- ギザギザした特徴の提示(Shows jaggedness)
- AIの不均一な能力分布を可視化
- AGI達成の具体的課題(長期記憶)を明確化
- 時間経過の追跡(Tracking metrics over time)
- GPT-4(2023年)→GPT-5(2025年)の進化を定量化
- 「巨大な飛躍(huge leap)」を数値で示す
- AGI達成時期の予測精度向上
Mollick教授が批判した「嫌いな点」:
- 人間認知モデルの再現として定義(AGI defined as replicating a model of human cognition)
- 問題点:人間と異なる知能形態を排除
- 具体例:昆虫の群知能、宇宙人の知能は「AGI」ではない?
- 哲学的疑問:なぜAGIは人間を模倣すべきか?
- ベンチマークが散漫(Benchmarks are scattershot)
- 問題点:10領域それぞれに複数のテストが存在し、統一評価が困難
- 具体例:流動的推論だけでレイブン・マトリックス、Wiscon カードソート、Tower of Hanoiなど多数
- 改善案:各領域に1つの標準ベンチマークを設定すべき
- AIの狭い視点(Narrow view of AI)
- 問題点:LLM中心の評価で、他のAI形態(ロボティクス、エージェント)を軽視
- 具体例:物理的世界での作業能力、社会的協調性は評価外
- 改善案:マルチモーダル・具現化AIの評価軸を追加
Mollick教授の結論:
「この論文は必要だが不完全。AGI定義の統一に向けた重要な一歩だが、人間中心主義とベンチマーク設計に課題が残る。今後の改訂で、より包括的な知能概念と標準化されたテスト体系が求められる」
– Ethan Mollick, @emollick
統一定義がもたらす未来──PR用語との闘い、真のマイルストーン設定
CHCモデルに基づく統一定義が広く採用されれば、AI業界に3つの革命的変化が起こります。
1. PR用語の終焉──「AGI」の乱用を防ぐ
現在、多くのAI企業が自社モデルを「AGI」または「AGI級」と宣伝していますが、具体的基準がないため実質的に無意味です。
統一定義後の変化:
- 企業が「AGI」と主張するには、10領域すべてで人間中央値以上を証明する義務
- 第三者機関による独立評価・認証
- 虚偽宣伝には法的責任(消費者保護法違反)
2. 投資判断の精密化──AGI達成時期の予測精度向上
統一定義により、投資家はAI企業の進捗を定量的に評価できます。
投資戦略への影響:
| 企業 | 10領域達成度 | AGI達成予測 | 投資判断 |
|---|---|---|---|
| OpenAI | 9/10達成(長期記憶のみ未達) | 2027-2028年 | 最優先投資 |
| Anthropic | 8/10達成(長期記憶・聴覚未達) | 2028-2030年 | 高優先投資 |
| Google DeepMind | 8/10達成(長期記憶・聴覚未達) | 2029-2032年 | 中優先投資 |
| Meta | 7/10達成 | 2035年以降 | 低優先 |
3. 規制の明確化──政府・国際機関の法制化
統一定義により、各国政府は「AGI規制法」を具体的に設計できます。
規制フレームワーク案:
- AGI達成前(7-9領域達成):開発報告義務、倫理審査
- AGI達成時(10領域達成):政府認証、安全性審査、使用制限
- AGI超越後(全領域で人間上位10%超):厳格な使用許可制、国際監視
日本への影響:
日本政府は「AI戦略会議」で、2026年までにAGI規制法案を国会提出予定です。CHCモデルに基づく統一定義が採用されれば、日本は世界で初めて「科学的根拠に基づくAGI規制」を実現する国となります。
まとめ:AGI定義統一への道のり、残された課題
CHCモデルに基づく統一定義は、AGI議論に科学的厳密性をもたらしました。しかし、実用化には3つの課題が残されています。
この記事の要点:
- 現在、OpenAI、Google DeepMindなど企業ごとに異なるAGI定義が乱立
- CHCモデルに基づく統一定義:10の認知領域すべてで人間中央値以上
- GPT-5は9/10領域で達成も、長期記憶の欠如によりAGIではない
- Ethan Mollick教授の批判:人間中心主義、ベンチマークの散漫さ、AIの狭い視点
- 統一定義によりPR用語の乱用防止、投資判断精密化、規制明確化が可能に
残された3つの課題:
- ベンチマークの標準化
- 各認知領域に1つの標準テストを設定
- 第三者機関による認証プロセス確立
- 人間中心主義の克服
- 人間と異なる知能形態(宇宙人、昆虫など)の評価軸
- 具現化AI(ロボティクス)の評価基準追加
- 長期記憶の技術的突破
- コンテキストウィンドウ外の情報保持
- セッション間の学習内容維持
- 人間のエピソード記憶に相当する機能
2027年、GPT-6がリリースされる時、私たちは初めて「真のAGI」を目撃するかもしれません。その判断基準は、もはや企業の主観ではなく、CHCモデルの10領域という科学的指標によって決まるのです。
関連記事:
コメント