

医療AI分野で歴史的瞬間が訪れました。Google DeepMindのGemini 3.0 Proが、放射線科の最難関ベンチマーク「RadLE v1」で51%の精度を達成し、放射線科研修医の45%を上回りました。
これは、汎用AIモデルが初めて研修医レベルを超えたという画期的な成果です。ただし、認定放射線科医の約83%にはまだ遠く及びません。
最も重要なのは、このベンチマークが「実際の使用事例を示している」という点です。多くのベンチマークが理論的な性能指標に過ぎないのに対し、RadLEは実臨床で直面する複雑な診断パズルを扱います。
本記事では、Gemini 3.0の驚異的成績、他のAIモデル(GPT-5、o3、Grok 4)との比較、そして「放射線科医の終わり」という過激な見出しの真実を徹底分析します。

RadLEベンチマークとは:「放射線科医の最後の試験」
RadLE(Radiology’s Last Exam)v1は、Ashoka UniversityのCRASH Lab(Centre for Responsible Autonomous Systems in Healthcare)が開発した、医療AI分野で最も困難な視覚推論ベンチマークです。
Dr. Datta AIIMS(放射線科医)の発言:
「医療における最も困難な視覚推論ベンチマークでGemini 3.0はどうだったのか?という質問がメールボックスに殺到した。だから我々は試験を実施した」
– X (Twitter) 2025年11月20日
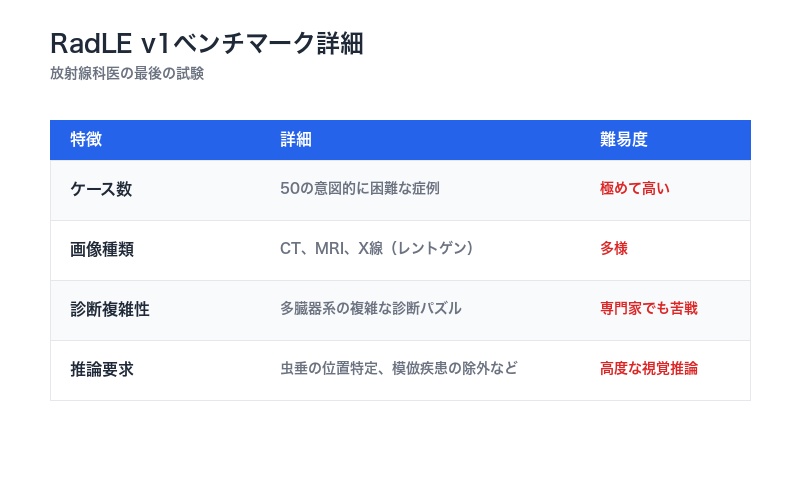
このベンチマークが「最後の試験」と呼ばれる理由は、以下の特徴にあります。
| 特徴 | 詳細 | 難易度 |
|---|---|---|
| ケース数 | 50の意図的に困難な症例 | 極めて高い |
| 画像種類 | CT、MRI、X線(レントゲン) | 多様 |
| 診断複雑性 | 多臓器系の複雑な診断パズル | 専門家でも苦戦 |
| 推論要求 | 虫垂の位置特定、模倣疾患の除外など | 高度な視覚推論 |
RadLEは、単なる画像認識テストではありません。経験豊富な放射線科医でさえ頭を悩ませる、実際の臨床で遭遇する困難症例を集めたものです。
Gemini 3.0の驚異的成績:史上初の快挙
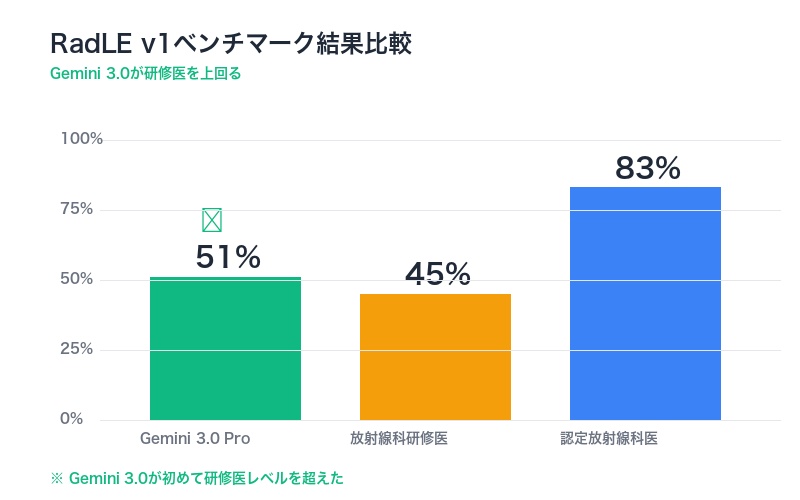
2025年11月20日、CRASH Labが発表したGemini 3.0 ProのRadLE v1結果は、医療AI業界に衝撃を与えました。
| 対象 | 精度 | 評価 |
|---|---|---|
| Gemini 3.0 Pro | 51% | 🏆 史上初:汎用モデルが研修医超え |
| 放射線科研修医 | 45% | トレーニング中の医師 |
| 認定放射線科医 | 約83% | 🥇 最高レベル |
この成績の意味するところは重大です。
- 史上初の快挙:汎用AIモデルが放射線科研修医の基準を超えた
- ステップバイステップ推論:難しいケースで明確な論理展開を示した
- 虫垂位置特定:複雑な解剖学的位置関係の理解
- 模倣疾患の除外:似た症状を持つ別の疾患の識別
しかし、同時に認定医83%との大きなギャップも明らかになりました。これは、AIがまだ独立した診断を行える段階にはないことを示しています。
他のAIモデルとの圧倒的差:GPT-5、o3を大きく引き離す
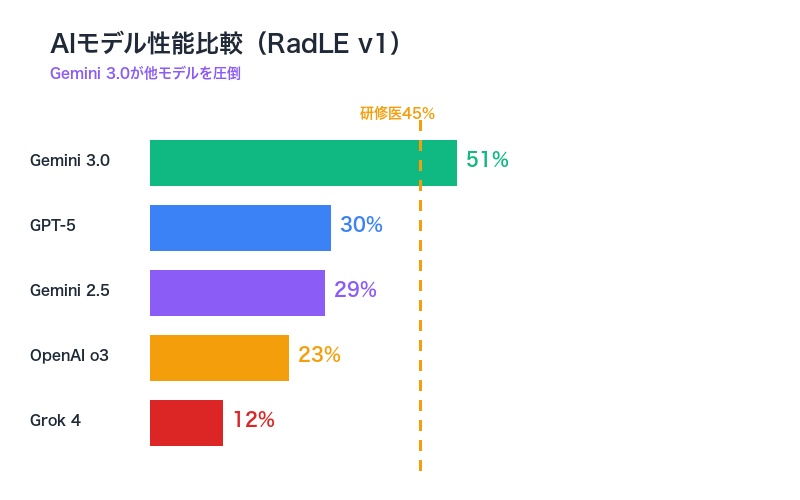
Gemini 3.0の51%という成績は、他の最先端AIモデルと比較すると、その凄さが際立ちます。
2025年9月時点で実施された同じRadLE v1ベンチマークでは、全ての主要モデルが研修医レベル(45%)を下回っていました。
| AIモデル | 精度(2025年9月) | Gemini 3.0との差 |
|---|---|---|
| Gemini 3.0 Pro | 51% | – |
| GPT-5 thinking | 30% | -21ポイント |
| Gemini 2.5 Pro | 29% | -22ポイント |
| OpenAI o3 | 23% | -28ポイント |
| Grok 4 | 12% | -39ポイント |
| 放射線科研修医 | 45% | -6ポイント |
この比較から明らかなのは、わずか2ヶ月でGemini 3.0が21ポイントもの性能向上を達成したということです(Gemini 2.5 Proの29%から51%へ)。
なぜGemini 3.0は他を圧倒したのか?
- マルチモーダル能力の強化:画像とテキストの統合理解
- 医療特化型トレーニング:Med-Geminiプロジェクトの成果
- 推論チェーンの改善:ステップバイステップの論理展開
- 大規模医療データ学習:CT、MRI、X線の膨大な学習データ
なぜこのベンチマークが重要なのか:「実際の使用事例」を示す意義
AI専門家Chubbyは、このベンチマークの重要性を以下のように述べています。
Chubbyの見解:
「このベンチマークは他のほとんどのものよりも私にとって興味深い。なぜなら、実際の使用事例を示しているからだ。つまり、実際の利益を示している。Gemini 3.0が放射線科研修医を上回ったのは驚くべきことだ」
– X (Twitter) 2025年11月20日
多くのAIベンチマークは、理論的な性能指標に過ぎません。しかし、RadLEは異なります。
| ベンチマーク種類 | 特徴 | 実用性 |
|---|---|---|
| 一般的なベンチマーク | 理論的性能、抽象的タスク | ⭐⭐ |
| RadLE v1 | 実臨床の困難症例、実際の診断プロセス | ⭐⭐⭐⭐⭐ |
RadLEが示す「実際の利益」とは、以下のような具体的な医療現場での活用可能性です。
- 初期診断支援:研修医レベルのAIが24時間体制でトリアージ
- セカンドオピニオン:見落とし防止のダブルチェック
- 地方医療の補完:専門医不在地域での診断サポート
- 教育ツール:研修医のトレーニング支援
- 負担軽減:放射線科医の過重労働の緩和

放射線科医の未来:「ゲームオーバー」は誤解
Dr. Datta AIMSの投稿には、「☠️ Is it game over for Radiology?(放射線科の終わりか?)」という衝撃的な見出しがありました。
しかし、結論から言えば、放射線科医の役割は終わるどころか、むしろ進化するというのが正確な見方です。
| 誤解 | 現実 |
|---|---|
| ❌ AIが放射線科医を完全に置き換える | ✅ AIは補助ツール、最終判断は人間 |
| ❌ 研修医を超えたので臨床使用可能 | ✅ 認定医83%には遠く及ばない |
| ❌ 画像読影だけが放射線科医の仕事 | ✅ 総合的診断、患者対応、治療方針決定 |
重要なのは、「AIが画像を読む。放射線科医が決断を下す」という役割分担です。
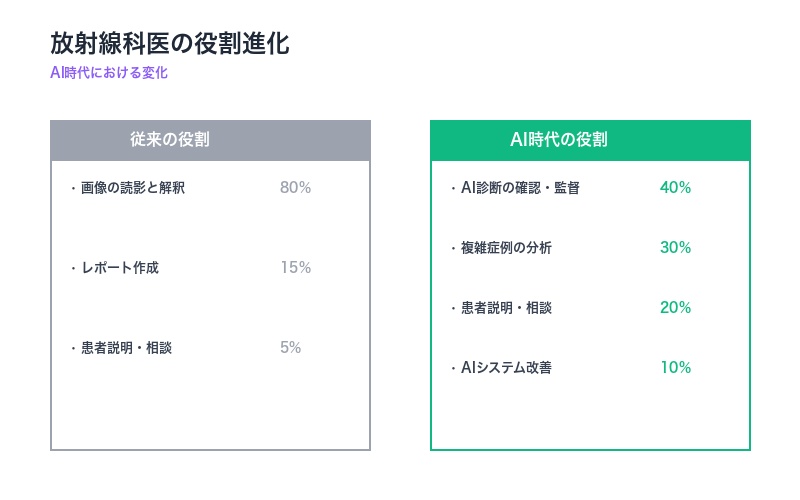
放射線科医の役割の進化
従来の役割
- 画像の読影と解釈(時間の80%)
- レポート作成(時間の15%)
- 患者説明・治療方針相談(時間の5%)
AI時代の役割
- AIの診断確認と監督(時間の40%)
- 複雑症例の深掘り分析(時間の30%)
- 患者説明・治療方針相談(時間の20%)
- AIシステムの改善フィードバック(時間の10%)
Dr. Vishal Sengarは、Threadsで以下のように述べています。
「恐ろしい見出しか? はい。放射線科の終わりか? いいえ。AIは画像を読む。放射線科医は決断を下す。未来は、AIを恐れる医師ではなく、AIを使いこなす医師のものだ」
臨床展開への3つの壁:まだ遠い実用化
Gemini 3.0の成果は素晴らしいものですが、実際の臨床現場への展開にはまだ大きな障壁があります。CRASH Labの研究者は慎重な見解を示しています。
CRASH Labの警告:
「我々はまだ、展開、自律性、診断置き換えの準備ができていない。AIシステムは、独立した臨床意思決定に必要な信頼性にはまだ達していない」
| 壁 | 詳細 | 克服困難度 |
|---|---|---|
| 1. 精度の壁 | 51% vs 認定医83%の巨大ギャップ | ⭐⭐⭐⭐⭐ |
| 2. 信頼性の壁 | 誤診のリスク、法的責任の所在 | ⭐⭐⭐⭐⭐ |
| 3. 規制の壁 | 医療機器承認、臨床試験の必要性 | ⭐⭐⭐⭐ |
特に深刻なのは、精度の壁です。51%と83%の差は、数字以上に大きな意味を持ちます。
- 誤診リスク:49%の症例で誤った判断の可能性
- 見落とし:重篤な疾患を見逃すリスク
- 過剰診断:不要な検査や治療の誘発
- 患者の信頼:AIのみの診断への不安
臨床展開に必要な条件
- 精度95%以上:認定医レベルの信頼性
- 透明性の確保:診断根拠の説明可能性
- 臨床試験:大規模な前向き研究での検証
- 規制当局の承認:FDA、PMDAなどの認可
- 医師の監督:必ず人間の医師が最終確認

医療AI進化のタイムライン:2030年までのロードマップ
では、Gemini 3.0レベルのAIが実際の臨床現場で活用されるのは、いつ頃になるのでしょうか?
専門家の見解と現状の技術進歩を総合すると、以下のようなタイムラインが浮かび上がります。
医療AI実用化のタイムライン
現在(2025年)
- ✅ ベンチマークで研修医超え達成
- ✅ 研究段階での有用性実証
- ❌ 臨床展開には未対応
短期(2026〜2027年)
- 臨床試験の開始(限定的な環境下)
- 補助ツールとしての試験導入
- 精度70-75%への改善
- 役割:研修医のトレーニング支援
中期(2028〜2030年)
- 特定疾患での実用化(肺がん、骨折など)
- セカンドオピニオンツールとしての普及
- 精度85-90%への到達
- 役割:放射線科医の負担軽減ツール
長期(2030年以降)
- 幅広い疾患での実用化
- 地方医療での診断支援システム
- 精度95%以上の達成
- 役割:医師と協働する診断パートナー
重要なのは、どの段階でも「人間の医師による最終確認」が必須だということです。完全自律型の診断AIが臨床で使われることは、少なくとも2030年代前半には想定されていません。
| 時期 | 精度目標 | 主な用途 | 医師の役割 |
|---|---|---|---|
| 2025年 | 51% | 研究・開発 | 完全独立 |
| 2026-2027年 | 70-75% | トレーニング支援 | 全症例確認 |
| 2028-2030年 | 85-90% | 負担軽減ツール | 重要症例確認 |
| 2030年以降 | 95%+ | 診断パートナー | 最終判断・監督 |

AIと人間の協働モデル:未来の医療現場
最も現実的で望ましい未来像は、AIと人間の医師が協働する医療体制です。
この協働モデルでは、それぞれの強みを活かした役割分担が行われます。
| 主体 | 得意分野 | 担当業務 |
|---|---|---|
| AI(Gemini 3.0等) |
パターン認識
大量データ処理 24時間稼働 疲労なし |
初期スクリーニング
異常検出 候補診断リスト作成 見落とし防止チェック |
| 人間の放射線科医 |
文脈理解
複雑な推論 患者との対話 倫理的判断 |
最終診断決定
複雑症例の分析 患者説明 治療方針決定 |
この協働モデルの具体的なワークフローは以下のようになります。
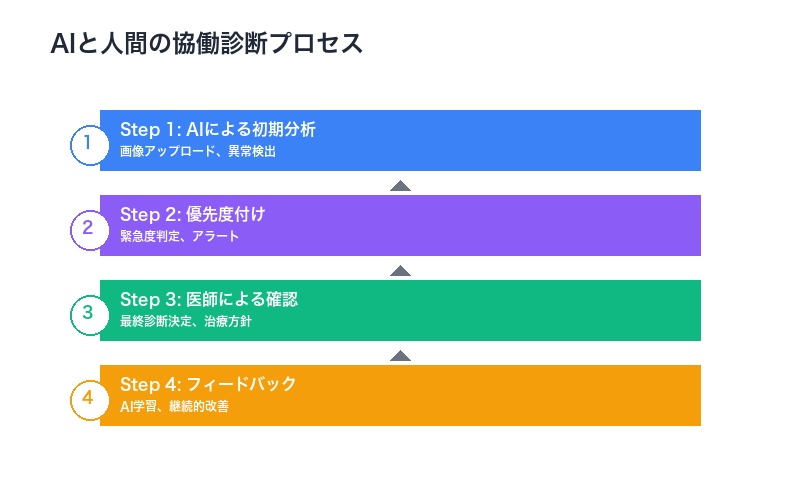
AI+人間協働の診断プロセス
- Step 1:AIによる初期分析
- 画像のアップロードと自動スクリーニング
- 異常所見の検出と位置特定
- 候補診断のリストアップ(確率付き)
- Step 2:優先度付け
- 緊急度の高い症例を自動抽出
- 医師への通知とアラート
- Step 3:人間医師による確認
- AIの診断候補を参照しながら詳細分析
- 患者の病歴、臨床情報との統合
- 最終診断の決定
- Step 4:フィードバック
- 医師の診断をAIに学習させる
- システムの継続的改善
この協働モデルにより、以下のような具体的メリットが期待されます。
- 診断速度の向上:初期スクリーニングの自動化により30-50%時間短縮
- 見落とし率の低減:AIのダブルチェックにより誤診リスク減少
- 医師の負担軽減:ルーチン業務の削減、複雑症例に集中可能
- 地方医療の強化:専門医不在地域でもAI支援により質の高い診断
- 教育効果:研修医がAIの診断プロセスから学習
This benchmark interests me more than most others. Why? Because this benchmark demonstrates a real-world use case, i.e., it shows a real benefit; Gemini 3.0 now outperforms radiologist trainees.
— Chubby♨️ (@kimmonismus) November 20, 2025
This is phenomenal. pic.twitter.com/8k5yYNkUtA
まとめ
Google DeepMindのGemini 3.0 Proが、放射線科の最難関ベンチマークRadLE v1で51%の精度を達成し、研修医の45%を上回ったことは、医療AI史上の画期的な成果です。
ただし、現実を冷静に見る必要があります。
- 歴史的快挙:汎用AIモデルで初めて研修医レベルを超えた
- 実用性の証明:理論ではなく「実際の使用事例」を示すベンチマーク
- 他モデルを圧倒:GPT-5(30%)、o3(23%)を大きく引き離す
- しかし課題も多い:認定医83%とのギャップ、信頼性、規制の壁
- 臨床展開は段階的:2030年頃まで補助ツールとしての活用
最も重要なのは、「AIが医師を置き換える」のではなく「AIと医師が協働する」という未来像です。AIを恐れるのではなく、AIを使いこなす医師こそが、これからの医療を担います。
Gemini 3.0の成果は、医療AIの可能性を大きく前進させました。しかし、患者の命を預かる医療現場では、慎重かつ段階的なアプローチが不可欠です。
Sources:
コメント