

AI業界を震撼させる暴露記事がThe Informationから発表されました。OpenAIが「Google検索の競合」を標榜しながら、裏ではGoogle検索結果を密かにスクレイピングしていたという、業界の偽善を暴く衝撃的な事実です。
更に驚愕すべきは、この不正行為にはPerplexity、Meta、Appleといったテック業界の巨人たちも関与していることが判明。ChatGPTの週間7億ユーザーへの回答の一部は、実はGoogleのデータを転用したものだったのです。
8年前に設立されたスタートアップ「SerpApi」を隠れ蓑にした、この巧妙な情報窃取スキーム。昨年5月までOpenAIを顧客として公然と掲載していたSerpApiが、なぜその記載を突然削除したのか?Googleが法的対抗措置を取れない理由とは?業界の闇を徹底解剖します。
The Information独占報道:OpenAIの秘密工作が白日の下に
テック業界の権威あるメディア「The Information」が2025年1月に発表した調査報道は、AI検索競争の偽りの構図を完全に暴露しました。OpenAIがChatGPTでGoogle検索に対抗すると宣言しながら、実際にはその競合相手からデータを密かに調達していたという、前代未聞のスキャンダルです。

スキャンダルの核心事実
The Informationの詳細調査により判明した驚愕の事実:
- 秘密の下請け:OpenAIは直接Google検索にアクセスできないため、SerpApiを仲介業者として利用
- リアルタイム情報の裏側:ChatGPTのニュース、スポーツ、金融市場情報は実はGoogle検索結果の転用
- 隠蔽工作:2024年5月まで公然と顧客として掲載されていたOpenAIが突然リストから消える
- 共犯者の存在:Perplexity、Meta、Apple等の大手企業も同様にSerpApiを利用
元Google エンジニアによる検証実験:
Abhishek Iyer氏は、Google検索インデックスにのみ存在するダミーページを作成。その後ChatGPTに同じ内容について質問したところ、そのダミーページの情報を正確に回答。これがOpenAIのGoogle依存を決定的に証明しました。
Googleからの直接拒否が招いた迂回作戦
司法省の反トラスト訴訟で明らかになった文書によると、OpenAIは直接Googleに検索インデックスへのアクセスを要求したが拒否されたことが判明しています。この拒否が、SerpApiを通じた「迂回作戦」の引き金となったのです。
| 時系列 | 出来事 | 関係者 |
|---|---|---|
| 2023年頃 | OpenAI、Google に検索インデックス提供を直接要請 | OpenAI ← Google(拒否) |
| 2024年前半 | SerpApi経由での大規模スクレイピング開始 | OpenAI ← SerpApi ← Google |
| 2024年5月 | SerpApi顧客リストからOpenAI削除 | SerpApi(隠蔽工作) |
| 2025年1月 | The Information がスキャンダルを暴露 | 報道機関 |
SerpApi:8年間の陰の実力者が暴かれた正体
今回の主役であるSerpApiは、2017年にテキサス州オースティンで設立されたウェブスクレイピング専門企業です。表向きは「検索結果の構造化API提供」を謳いながら、実際はGoogle検索結果の大規模転売業者として機能していました。
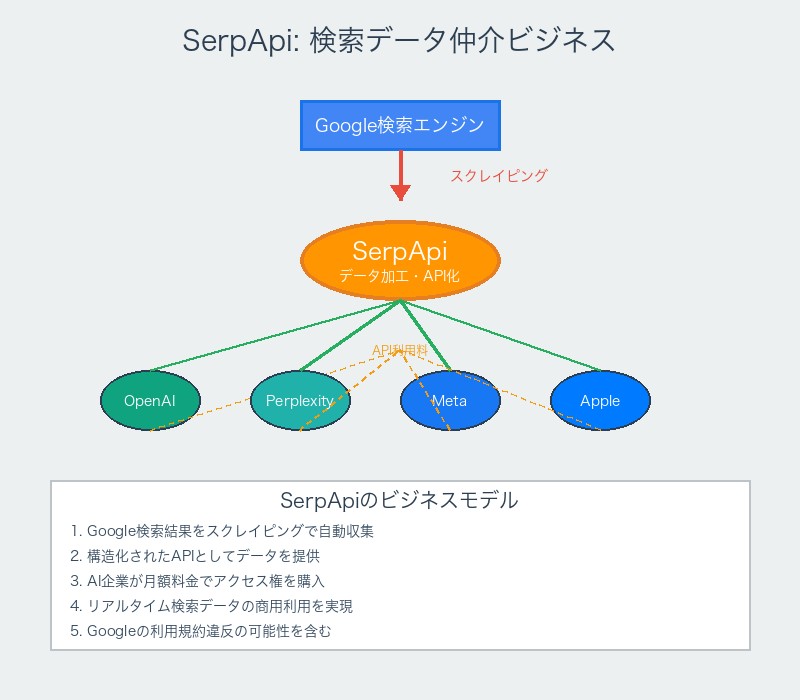
SerpApiの巧妙なビジネスモデル
「合法的」なスクレイピングサービスとして営業してきたSerpApiの実態:
- 技術的迂回:Google検索を自動化してAPI経由でデータ提供
- スケーラブル転売:1つのスクレイピングで複数企業にデータ販売
- 法的グレーゾーン:直接的な著作権侵害を回避する構造
- エンタープライズ対応:大量アクセスにも対応する技術力
豪華顧客リストの闇
SerpApiの顧客リストは、まさにシリコンバレーのWho’s Who状態でした:
| 企業名 | 利用目的(推測) | 市場ポジション |
|---|---|---|
| OpenAI | ChatGPTリアルタイム情報 | Googleの直接競合 |
| Perplexity | AI検索エンジン機能 | Googleの直接競合 |
| Meta | SNS関連情報収集 | 間接競合 |
| Apple | Siri情報強化 | 間接競合 |
特に注目すべきは、OpenAIとPerplexityという「Google検索の代替」を標榜する企業が、実際にはGoogleに完全依存していたという皮肉な事実です。
ChatGPT 7億ユーザーが知らなかった情報源の真実
週間アクティブユーザー数7億人、年間売上予測100億ドルという華々しい数字の裏で、ChatGPTの「知識」の一部がGoogle検索結果の転用だったという衝撃的な事実。ユーザーは完全に騙されていました。

リアルタイム情報の偽装メカニズム
OpenAIが特にGoogle依存していた分野:
- ニュース情報:最新の政治・経済・社会情勢
- スポーツ結果:リアルタイムスコアや試合結果
- 金融市場:株価、為替、仮想通貨の最新値
- 天気予報:地域別の詳細天気情報
- 交通情報:渋滞状況や電車遅延情報
これらの情報について、ChatGPTは「最新の情報を調べてお答えします」と回答しながら、実際にはGoogle検索結果をSerpApi経由で取得していたのです。
技術的検証:元Googleエンジニアの決定的実験
Abhishek Iyer氏(元Google検索エンジニア)が実施した検証実験は、この不正行為を科学的に証明しました:
実験手順:
- Google検索インデックスにのみ存在するダミーWebページを複数作成
- これらのページは他の検索エンジンには一切登録せず
- 作成から数日後、ChatGPTに同じトピックについて質問
- 結果:ChatGPTがダミーページの内容を正確に引用
結論:ChatGPTがGoogle検索結果を直接利用している決定的証拠
OpenAIの言い訳と現実のギャップ
OpenAIは公式には「自社検索インデックスの80%を目標」と発表していますが、現実は程遠い状況です:
| 指標 | OpenAIの主張 | 実際の状況 |
|---|---|---|
| 自社インデックス率 | 80%を目標 | 実際は大幅に未達 |
| リアルタイム情報 | 独自収集 | Googleデータに依存 |
| 競合関係 | Google検索の代替 | 実はGoogle寄生虫 |
Perplexity:「AI検索の純粋性」という偽りの看板
OpenAI以上に深刻なのが、「AI検索のピュアプレイヤー」として注目を集めてきたPerplexityです。同社もSerpApiの大口顧客であることが判明し、その「純粋性」は完全に偽装だったことが明らかになりました。

Perplexityの欺瞞的マーケティング
Perplexityが展開してきた欺瞞的なブランディング:
- 「Answer Engine」:従来検索とは異なる新カテゴリーと主張
- 「AI Native検索」:AI技術を基盤とした独自検索を標榜
- 「情報統合力」:複数ソースからの高度な分析を宣伝
- 「引用の透明性」:情報源の明示を差別化ポイントに
しかし実態は、Google検索結果をSerpApi経由で取得し、それをAIで要約・再構成していただけだったのです。
「引用の透明性」という最大の皮肉
Perplexityが競合優位性として最も強調していた「引用の透明性」。しかし、その引用元情報自体がGoogle検索結果の転用であり、真の情報源を隠蔽していたという事実は、業界最大級の皮肉と言えるでしょう。
Perplexityのジレンマ:ユーザーには情報源を明示しながら、その情報源の取得方法(Google依存)は完全に隠蔽。表向きの透明性と裏側の不透明性が共存する矛盾したビジネスモデル。
Meta・Apple:大手テック企業も共犯者だった証拠
この不正スキームの規模をさらに拡大させているのが、Meta(Facebook)とAppleという業界巨人の関与です。両社もSerpApiの顧客であることが判明し、Google検索データの組織的流用が業界全体に蔓延していることが明らかになりました。

Meta:SNS情報収集の陰の手法
Meta(Facebook、Instagram)のSerpApi利用目的:
- トレンド把握:リアルタイムの話題や関心事の特定
- コンテンツ推奨:ユーザーの興味に合わせた情報提供
- 広告ターゲティング:検索トレンドを活用した精密な広告配信
- 競合分析:他プラットフォームでの情報流通状況の監視
Apple:Siri強化の裏にGoogleデータ
AppleがSerpApiを利用している分野:
- Siri応答改善:音声アシスタントのリアルタイム情報提供
- Spotlight検索:Mac・iPhone内蔵検索の情報ソース
- アプリ推奨:App Storeでのアプリ発見・推奨システム
- ニュースアプリ:Apple News での情報キュレーション
業界全体のモラルハザード
これらの事実は、シリコンバレーの倫理的破綻を示している:
| 企業 | 公的立場 | 実際の行動 |
|---|---|---|
| OpenAI | Googleの代替を目指す | Googleデータに寄生 |
| Perplexity | 純粋なAI検索 | Google検索の焼き直し |
| Meta | 独自エコシステム | 外部データに依存 |
| Apple | プライバシー重視 | データ流用に加担 |
なぜGoogleは法的対抗措置を取れないのか?
最も不可解なのは、Googleがこれほど大規模な不正利用に対して法的対抗措置を取っていないことです。その背景には、同社が直面している複雑な法的・政治的状況があります。

司法省反トラスト訴訟の重圧
Googleが積極的な対応を取れない3つの法的制約:
- 独占的地位の証明回避:SerpApiを潰すことで「市場支配力の濫用」の証拠を与えるリスク
- 検索インデックス開放圧力:司法省がGoogle検索の開放を要求している状況
- 競争促進の建前:競合他社の成長を阻害すると批判される可能性
政治的配慮と戦略的判断
Googleの複雑な計算:
Google内部の戦略的ジレンマ:
「SerpApi経由の不正利用を法的に阻止すれば、司法省に『検索市場の独占維持』の口実を与える。一方で放置すれば、自社データが競合に無償提供される。どちらを選んでも不利益は避けられない」
技術的対抗措置の限界
Googleが取り得る技術的対策とその問題点:
- アクセス制限強化:正常なユーザーにも影響し、UX低下のリスク
- API利用料徴収:独占的地位の濫用と見なされる可能性
- 法的警告:競争阻害行為として司法当局に問題視される危険
- 技術的封鎖:イタチごっこになり、根本的解決にならない
業界への波及効果:AI検索競争の根本的欺瞒が露呈
この暴露により、AI検索革命として喧伝されてきた競争の実態が、実は既存検索エンジンへの寄生行為だったことが明らかになりました。業界全体の信頼性が根本から揺らいでいます。

投資家への深刻な影響
このスキャンダルがもたらす投資環境への衝撃:
- バリュエーション見直し:「革新的技術」ではなく「データ転売業」としての再評価
- 成長性質問:Googleが対策を講じた場合の事業継続性への懸念
- 法的リスク:著作権侵害や不正競争防止法違反の潜在的責任
- ESG評価低下:企業統治・倫理面での投資適格性に疑問符
ユーザー信頼の決定的損失
週間7億ユーザーを抱えるChatGPTへの信頼失墜の深刻さ:
| 信頼要素 | ユーザー期待 | 実際の状況 |
|---|---|---|
| 情報源の独自性 | OpenAI独自の知識ベース | Googleデータの転用 |
| 技術革新性 | 革命的AI検索技術 | 既存検索の焼き直し |
| 企業倫理 | 透明で公正な情報提供 | 隠蔽と欺瞒 |
競合関係の再定義
この暴露により、AI検索の競争構造が根本的に見直されます:
新たな競争の定義:
「Google vs AI検索」という構図は虚構であり、実際は「Googleのデータ利用権を巡る寄生虫同士の競争」が真実。本当の技術革新は、Google依存からの脱却を果たした企業のみが実現できる。
法的・倫理的問題の深刻性
このスキャンダルは、単なるビジネス問題を超えて、知的財産権・不正競争・企業統治における重大な法的問題を提起しています。

著作権侵害の可能性
Google検索結果の無断転用に関する法的論点:
- 検索結果の著作物性:Google検索結果のランキング・要約が独創的表現に該当するか
- フェアユース適用:商業利用における著作権制限規定の適用可否
- 間接侵害責任:SerpApi経由でも著作権侵害の共同責任が発生するか
- 損害の立証:Googleの経済的損失と因果関係の証明可能性
不正競争防止法違反
競合他社のデータを無断利用する行為の不正競争該当性:
- 営業秘密侵害:Google検索アルゴリズムの成果物利用
- 顧客誘引:Google検索結果と誤認させる表示
- 信用毀損:競合サービスとしての不当な優位性獲得
- 営業上の利益侵害:Googleの検索広告収入への悪影響
証券法上の問題
上場企業・投資対象企業としての情報開示義務違反:
重要事実の不開示:OpenAIやPerplexityが投資家に対してGoogle依存の事実を隠蔽していた場合、証券詐欺に該当する可能性。特に「革新的AI技術」としてのマーケティングは、実態とのかい離が著しく重大な誤解を与える。
業界再編への影響:真の技術革新企業の台頭
このスキャンダルは、AI検索業界の健全な再編を促進する可能性があります。Google依存から脱却した企業のみが、真の技術革新企業として評価されることになるでしょう。

真の技術革新企業の条件
今後評価される「本物のAI検索企業」の条件:
- 独自インデックス構築:自社でWeb クローリング・インデックス化を実施
- オリジナル AI アルゴリズム:検索・ランキング・要約の独自技術開発
- 透明な情報源表示:データ取得方法の完全開示
- 持続可能な事業モデル:外部依存ではない自立型収益構造
投資・評価基準の変化
投資家・ユーザーの新たな評価基準:
| 評価項目 | 従来基準 | 新基準 |
|---|---|---|
| 技術革新性 | AI活用の有無 | 独自技術の実装度 |
| 事業持続性 | ユーザー数・売上 | 外部依存度の低さ |
| 企業信頼性 | マーケティング力 | 透明性・誠実性 |
新興企業への機会創出
既存大手の信頼失墜は、真摯な技術開発を行う新興企業にとって大きなチャンスです:
- 差別化の明確化:「Google非依存」が強力なUSPになる
- 投資機会拡大:健全な技術企業への資金集中
- 人材獲得機会:倫理的企業への優秀人材の転職増加
- パートナーシップ:信頼できる企業との連携強化
今後の展望:AI検索の健全な発展に向けて
このスキャンダルは短期的には業界の混乱を招きますが、長期的にはAI検索の健全な発展への転換点となる可能性があります。

規制・ガイドライン整備の必要性
今回の事件を受けて整備すべき業界ルール:
- 情報源開示義務:AI サービスはデータ取得元の詳細開示を義務化
- 不正競争防止:競合他社データの無断利用に対する厳格な規制
- ユーザー保護:誤解を招くマーケティング表現の禁止
- 技術監査制度:第三者機関による独立性・透明性の定期監査
企業が取るべき対応策
AI検索関連企業の今後の対応指針:
- 完全な透明性:データ取得・処理方法の全面開示
- 独自技術投資:外部依存からの段階的脱却
- 倫理委員会設置:企業内での自己監査体制構築
- ステークホルダー対話:ユーザー・投資家との信頼関係再構築
ユーザーの賢い選択基準
今後ユーザーがAI検索サービスを選ぶ際の推奨チェックポイント:
ユーザーの自衛策:
- 情報源の開示状況を確認
- 独自技術の有無をチェック
- 過去の企業行動の透明性を評価
- 複数サービスを使い分けてリスク分散
- 重要な判断は元情報を直接確認
まとめ:偽りのAI革命から真の技術革新へ
OpenAIのGoogle検索データ不正利用スキャンダルは、AI検索革命の虚構性を白日の下に晒しました。しかし、この暴露は同時に業界の健全化への第一歩でもあります。

明らかになった業界の真実
- AI検索の多くは既存検索エンジンの寄生虫に過ぎなかった
- 「革新的技術」は実は隠蔽された データ転売ビジネスだった
- 業界全体でユーザーを欺く組織的な隠蔽工作が行われていた
- 投資家は技術革新ではなく不正行為に投資していた可能性
今後の健全化への道筋
このスキャンダルを契機として:
- 透明性の徹底:すべての AI サービスがデータ取得方法を開示
- 独自技術の重視:外部依存ではない本物の技術革新が評価される
- 規制の整備:不正競争を防止する業界ルールの確立
- ユーザー意識向上:サービス選択における判断基準の向上
最終的な提言
真の技術革新への転換:
このスキャンダルは一時的には業界の信頼を失墜させますが、長期的には本物の技術企業と偽物の淘汰を促進します。ユーザー、投資家、規制当局が一体となって透明性を要求することで、真に革新的で持続可能なAI検索の未来が実現できるでしょう。
偽りのAI革命は終わりました。今こそ、真の技術革新に基づく健全な競争の時代の始まりです。私たちユーザーの賢い選択が、業界の健全な発展を促進する原動力となるのです。
コメント