

「AIエージェントは、真の従業員として機能するには程遠い。記憶力、マルチモーダル性、真の学習能力が欠けている。それを修正するには約10年かかる──不可能だからではなく、深い知能を構築するには時間がかかるからだ」
元Tesla AI責任者、OpenAI創設メンバーのアンドレイ・カルパシー氏が、Dwarkesh Podcastで語った 「エージェントの10年」理論が、AI業界に大きな波紋を広げています。
Andrej Karpathy: AI agents like Claude or Codex are still far from acting as real “employees.” They lack memory, multimodality, and true learning. Fixing that will take about a decade — not because it’s impossible, but because deep intelligence just takes time to build. https://t.co/m2Q10r3pwH
— Chubby♨️ (@kimmonismus) October 17, 2025
このKimmonismus氏による要約投稿は 39.5万ビューを記録し、元のDwarkeshポッドキャストは721万ビューに達しました。
カルパシー氏自身による補足投稿も 251万ビューを獲得し、AI業界の最前線にいるリーダーたちから注目を集めています。
カルパシー氏「AGIまで10年」発言の衝撃──SF系楽観論の5-10倍悲観的
カルパシー氏の「エージェントの10年」理論は、現在のAI業界の過剰な期待に冷や水を浴びせるものです。
カルパシー氏のX投稿より:
@karpathy「私のAIタイムラインは、サンフランシスコのAIパーティーやTwitterのタイムラインで見かける見解と比べて5~10倍悲観的です。しかし、AI否定論者や懐疑論者と比べると依然としてかなり楽観的です」
– 引用元:X (Twitter)
AGIまで10年が「強気」な理由:
| 現状の進捗 | 残された課題 |
|---|---|
| LLMで膨大な進歩 | 地味な統合作業(grunt work) |
| 基礎的な言語理解 | 物理世界へのセンサー・アクチュエーター接続 |
| 単一タスクでの高性能 | 社会的な調整・合意形成 |
| 実験環境での成功 | 安全・セキュリティ対策(脱獄、悪意ある操作) |
| ベンチマークでの高得点 | 世界の任意の仕事を人間より優先したいと思える存在 |
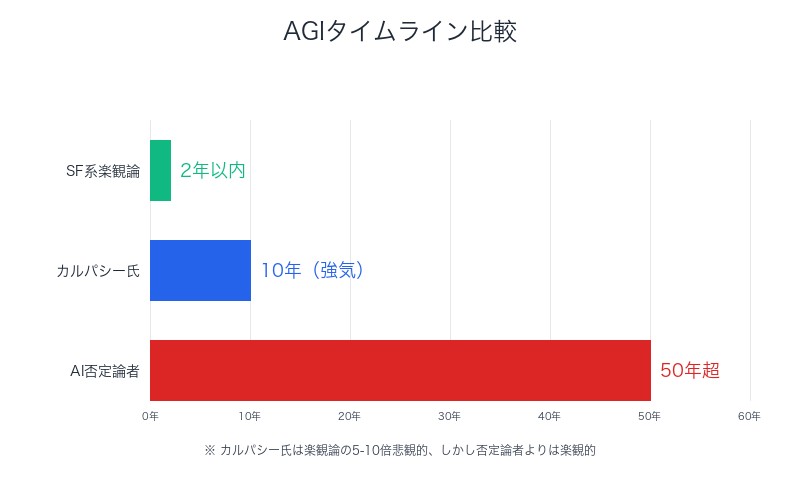
カルパシー氏は、現在のAI業界が「未来に生きている」と指摘します。完全自律型エンティティが並列で全てのコードを書き、人間は無用となる世界を前提にツールが設計されている──しかし現実はそこまで到達していないのです。
「幽霊 vs 動物」理論──LLMが持つ独自の知性形態
カルパシー氏の最も印象的な比喩は、LLMを「幽霊や精霊」と表現したことです。
なぜ動物ではなく幽霊なのか?
動物(例:生まれたばかりのシマウマ)は、進化によって膨大な知能を予め組み込まれています。彼らが実際に行う学習はごくわずかです。技術者の視点で言えば、我々は進化を再現しようとはしません。
しかしLLMは、進化ではなくインターネット上の次トークン予測によって、ニューラルネットワークに膨大な知能を「事前組み込み」する代替手法です。
幽霊の特性:
- 物理的制約がない: センサー・アクチュエーターを持たない
- 継続的な自己がない: セッションごとに記憶がリセット
- 進化の産物ではない: インターネットというデジタル空間から生まれた
- 身体性の欠如: 世界とのインタラクションが限定的
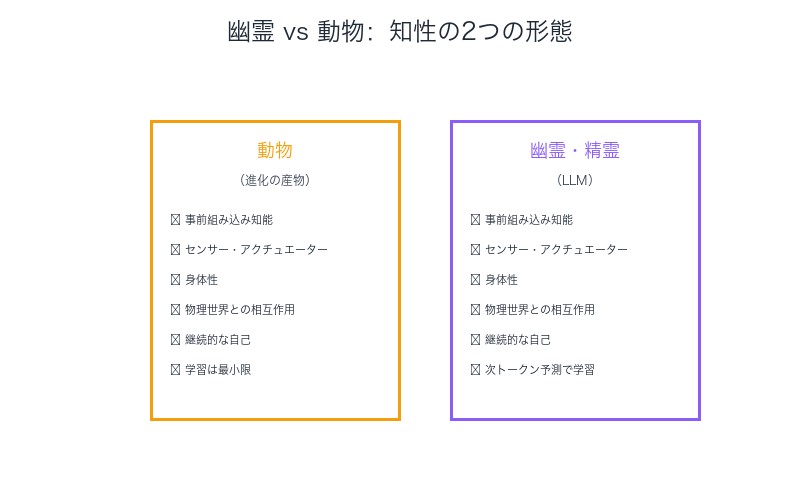
カルパシー氏は、「我々は(そしてそうすべきだ)時間をかけてそれらをより動物的にできる」と述べています。つまり、現在のフロンティア研究の多くは、幽霊を動物に近づける試みなのです。
強化学習への痛烈な批判──「ストローで監督を吸い込んでいる」
カルパシー氏は、現在主流となっている強化学習(RL)に対して痛烈な批判を展開しています。
カルパシー氏の表現:
「あなたは『ストローで監督を吸い込んでいる』ので、信号対雑音比が非常に悪い」
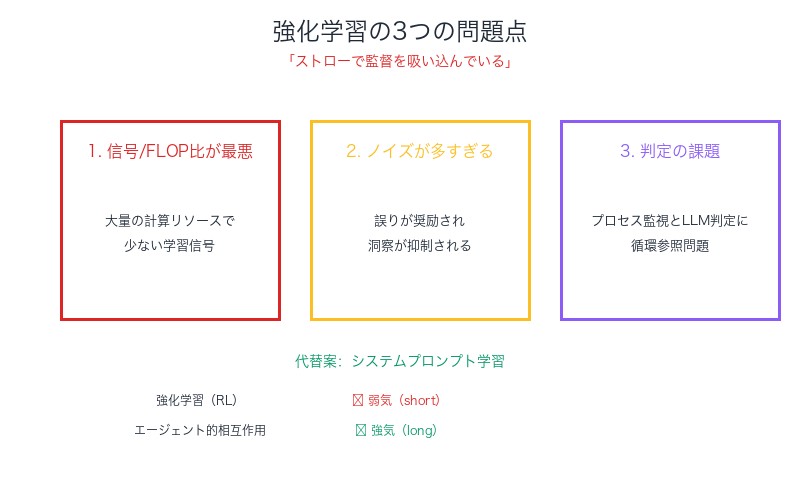
強化学習の3つの問題点:
1. 信号/FLOP比が最悪
大量の計算リソースを消費するにもかかわらず、得られる有用な学習信号は極めて少ない。これは「ストロー」という細い管を通して情報を吸い取る効率の悪さに例えられます。
2. ノイズが多すぎる
完了状態には多くの誤りが含まれていても(たまたま正解に辿り着いた場合)奨励される一方で、優れた洞察を示すトークンが(後で失敗した場合)抑制される可能性があります。
3. プロセス監視とLLM判定の課題
結果だけを見て報酬を与えるのではなく、プロセスを監視する必要があるが、これも完璧ではありません。LLMを判定者として使う手法も、循環参照的な問題を抱えています。
| 学習方法 | カルパシー氏の評価 |
|---|---|
| 強化学習(RL) | ❌ 弱気(short) |
| エージェント的相互作用 | ✅ 強気(long) |
| システムプロンプト学習 | ✅ 正しい方向 |
| ChatGPT記憶機能 | ✅ 新パラダイムの初期例 |
AIエージェントツールの過剰進化問題──1000行のコードを押し付けられたくない
カルパシー氏の業界への最も辛辣な批判は、現状の能力に対してツールが過剰に進化している点です。
カルパシー氏の理想と現実の乖離:
「私は20分間離れて1000行のコードを持ち帰るエージェントは望まない。ましてや10体のチームを監督する準備など全く整っていない」
カルパシー氏が望むAI協働の形:
- 頭の中で処理できる単位ごとに進める
- LLMが記述するコードを説明してほしい
- その正しさを証明してほしい
- APIドキュメントを参照し、正しく使用したことを示してほしい
- 推測を減らし、不明点があれば質問・協働してほしい
- その過程で学びながらプログラマーとして成長したい
過剰自動化のリスク:
| 問題 | 影響 |
|---|---|
| 粗悪なコードの山積 | ソフトウェア品質の全体的低下 |
| 脆弱性の増加 | セキュリティリスクの拡大 |
| ブラックボックス化 | メンテナンス不能なコードベース |
| 学習機会の喪失 | プログラマーのスキル劣化 |

カルパシー氏は、「ツールは、その能力と現在の業界における位置付けに関して、もっと現実的であるべき」と強調しています。
認知コア理論──記憶制限が汎化能力を生む
カルパシー氏の提唱する「認知コア」理論は、LLMの設計思想を根本から見直すものです。
認知コアの基本原理:
LLMを簡素化し、記憶を困難にしたり、積極的に記憶を剥奪することで、一般化能力を高める──という逆説的なアプローチです。
人間の記憶制限は「バグ」ではなく「機能」
人間はそれほど容易に記憶できませんが、これは対照的に、欠陥というよりむしろ長所のように見えます。おそらく記憶できないという特性は、一種の正則化と言えるでしょう。
モデルサイズのパラドックス:
カルパシー氏の洞察:
「モデルサイズのトレンドは『逆方向』である。モデルはまず巨大化してから初めて小型化できる」
これは、大規模モデルで学習した知識を、より小さく効率的なモデルに蒸留するアプローチを示唆しています。
| 従来の設計思想 | 認知コア理論 |
|---|---|
| 記憶容量の最大化 | 記憶制限による汎化促進 |
| パラメータ数の増加 | 大型化→蒸留→小型化 |
| 全ての情報を保持 | 重要な情報のみ保持 |
| 記憶に依存 | 推論能力に依存 |
システムプロンプト学習──ChatGPT記憶機能が示す新パラダイム
カルパシー氏は、強化学習に代わる「システムプロンプト学習」という新しいパラダイムに注目しています。
システムプロンプト学習とは?
従来のファインチューニングやRLではなく、システムプロンプト自体を学習・更新することで、LLMの振る舞いを改善する手法です。
ChatGPT記憶機能の意義:
カルパシー氏は、ChatGPTの記憶機能を「新しい学習パラダイムの初期段階での実例」と評価しています。
- ユーザーとの対話から学習
- 個別化された応答
- モデル本体を変更せずに振る舞いを調整
- 明示的な報酬関数なしでの最適化
arXivのアイデアと実装のギャップ:
カルパシー氏は、「arXiv上のアイデアと、LLM最先端研究所における汎用的な大規模実装との間には依然として隔たりがある」と指摘します。しかし、「近い将来に良い進展が見られると全体的に楽観視している」とも述べています。
真の「従業員」になるための3つの欠落──記憶・マルチモーダル・学習
Kimmonismus氏の要約が的確に指摘しているように、現在のAIエージェント(Claude、Codexなど)には、3つの致命的な欠落があります。
1. 記憶力(Memory)の欠如
現在のLLMは、セッションごとに記憶がリセットされます。長期的なプロジェクトを担当する従業員としては機能しません。
- 過去のやり取りを忘れる
- 継続的な学習ができない
- 個人の好みや文脈を保持できない
2. マルチモーダル性(Multimodality)の制限
人間の従業員は、視覚、聴覚、触覚など複数の感覚を使って世界を理解します。現在のAIエージェントは、主にテキストベースです。
- 物理世界との相互作用が限定的
- センサー・アクチュエーターの不足
- リアルタイムの環境認識ができない
3. 真の学習能力(True Learning)の欠如
現在のLLMは、事前学習とファインチューニングで固定されます。リアルタイムでの継続的な学習ができません。
- 新しい情報への適応が遅い
- ユーザー固有の知識を蓄積できない
- フィードバックループが不完全
| 能力 | 人間の従業員 | 現在のAIエージェント | 必要な進化 |
|---|---|---|---|
| 記憶 | ✅ 長期的 | ❌ セッション限定 | 永続的メモリシステム |
| マルチモーダル | ✅ 全感覚 | △ 主にテキスト | センサー・アクチュエーター統合 |
| 学習 | ✅ 継続的 | ❌ 固定 | リアルタイム学習パラダイム |
深い知能の構築には時間がかかる──10年の根拠
カルパシー氏が「10年」と見積もる根拠は、技術的な不可能性ではなく、深い知能の構築には本質的に時間がかかるという認識です。
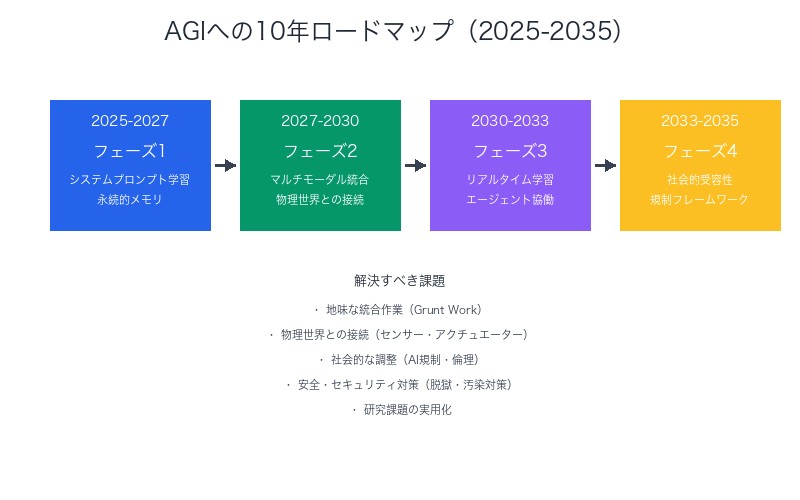
10年で解決すべき課題:
1. 地味な統合作業(Grunt Work)
華やかなブレークスルーではなく、膨大な地道なエンジニアリングが必要です。
2. 物理世界との接続
センサー、アクチュエーター、ロボティクスとの統合には、ソフトウェアだけでは解決できない課題があります。
3. 社会的な調整
AI規制、倫理的ガイドライン、社会的受容性の確立には時間がかかります。
4. 安全・セキュリティ対策
脱獄、悪意ある操作、データ汚染などへの対策は、いたちごっこが続くでしょう。
5. 研究課題の蓄積
システムプロンプト学習、認知コア、新しい学習パラダイムなど、まだ研究段階のアイデアを実用化する必要があります。
カルパシー氏の結論:
「10年というタイムラインはAGIにとって非常に強気な見通しだ。現在の過剰な期待と対比してそう感じられないだけだ」
現実的なロードマップ(2025-2035):
| 期間 | マイルストーン |
|---|---|
| 2025-2027 | システムプロンプト学習の実用化、永続的メモリの初期実装 |
| 2027-2030 | マルチモーダル統合の進展、物理世界とのインタラクション改善 |
| 2030-2033 | リアルタイム学習パラダイムの確立、エージェント協働の実用化 |
| 2033-2035 | 社会的受容性の確立、規制フレームワークの完成 |
まとめ:
アンドレイ・カルパシー氏の「エージェントの10年」理論は、AI業界の過剰な期待に対する冷静な現実認識です。
重要な洞察:
- AGIまで10年は「強気」──SF系楽観論の5-10倍悲観的だが、依然として楽観的
- LLMは「幽霊」──進化の産物である動物とは異なる知性形態
- 強化学習は問題だらけ──「ストローで監督を吸い込んでいる」
- ツールが能力を超えている──1000行のコードを押し付けるな
- 記憶制限は機能──認知コア理論による汎化能力向上
- システムプロンプト学習──ChatGPT記憶機能が示す新パラダイム
- 3つの欠落──記憶、マルチモーダル、真の学習
- 深い知能には時間がかかる──10年の根拠は技術的制約ではなく本質的複雑性
ClaudeやCodexのようなAIエージェントが真の「従業員」として機能するには、まだ長い道のりがあります。しかし、それは不可能ではなく、単に時間がかかるだけなのです。
カルパシー氏の視点は、AI業界に必要な現実的な期待値調整を提供しています。過度な楽観論でも悲観論でもない、バランスの取れた中間的立場──それが「エージェントの10年」の真意です。
コメント