
コンテキストエンジニアリングの「見落とされている課題」
AIエージェント開発において、コンテキストエンジニアリングが重要なアプローチとして注目されています。LLMに渡す文脈全体を設計し、最適な応答を引き出す技術です。
しかし、ここに見落とされがちな根本的な課題があります。
「情報の重要性をAIがうまく判別できない」
その原因は、ベクトル検索(単語の意味の近さで探すこと)が主な検索手法だから。
この課題を解決する次世代アプローチとして、メモリエンジニアリングが提唱されています。ベクトル検索だけに頼らない、多角的な情報の取得・更新を可能にする設計思想です。
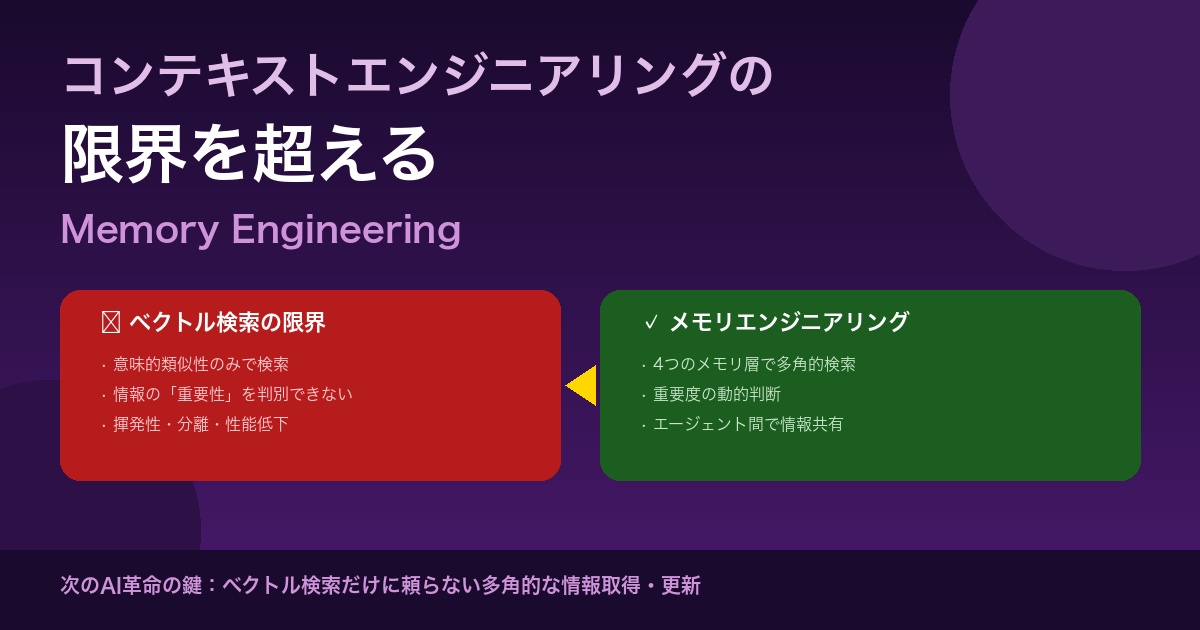
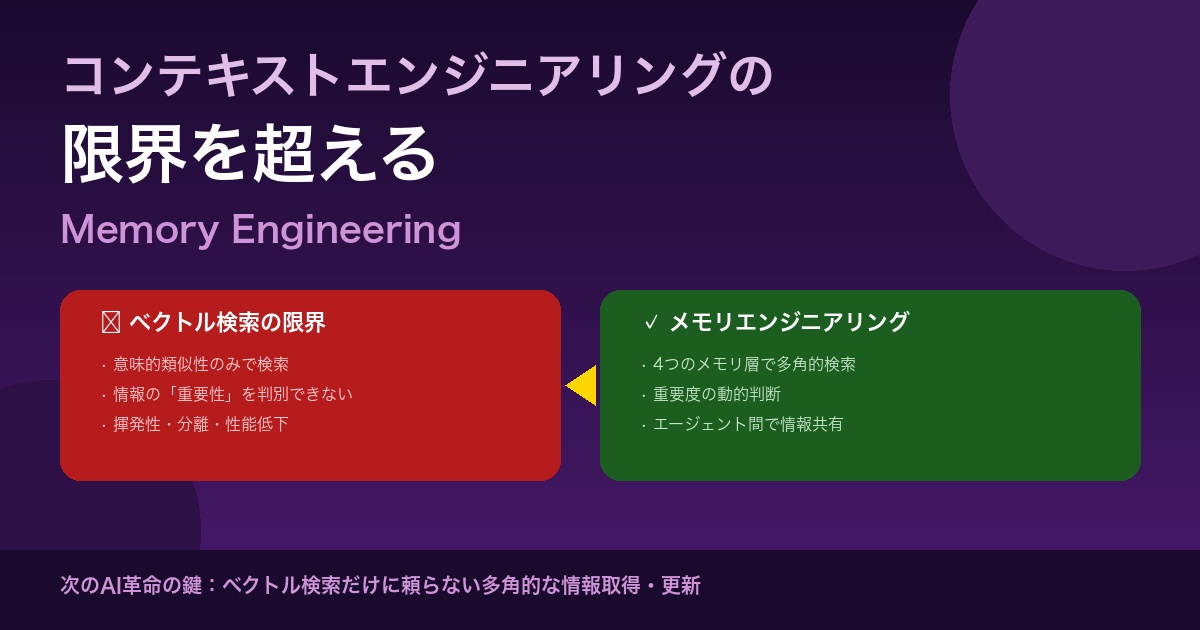
ベクトル検索の限界:なぜ「重要性」を判別できないのか
現在のAIシステムの多くは、ベクトル検索(セマンティック検索)を情報取得の中心に据えています。この手法には本質的な限界があります。
ベクトル検索の仕組み
| ステップ | 処理内容 | 問題点 |
|---|---|---|
| 1. 埋め込み生成 | テキストを数値ベクトルに変換 | 意味は捉えるが「重要度」は失われる |
| 2. 類似度計算 | コサイン類似度などで近さを測定 | 「近い」≠「重要」 |
| 3. 上位N件取得 | 最も類似した文書を返す | 文脈的重要性が考慮されない |
具体的な問題例
例えば、「プロジェクトの進捗」について質問した場合:
- ベクトル検索の結果:「進捗」という単語に意味的に近い文書を返す
- 本当に必要な情報:最新の状況、重要な決定事項、ブロッカーなど
ベクトル検索は「意味的な近さ」は捉えられますが、「今この瞬間にどれが重要か」を判断することはできません。

コンテキストウィンドウ拡張の「幻想」
「コンテキストウィンドウが大きくなれば解決する」—この考えは幻想です。
確かにLLMのコンテキストウィンドウは、この1年で指数関数的に拡大しました:
- 以前:数千〜数万トークン
- 現在:10万〜100万トークン級(Gemini、Claude等)
しかし、容量拡張だけでは3つの本質的な問題が解決されません。
| 問題 | 説明 | 影響 |
|---|---|---|
| 1. 性能低下 | 情報を詰め込みすぎると推論精度が低下 | 「迷子」になり、的確な回答ができない |
| 2. 揮発性 | セッション終了で情報が消失 | 毎回ゼロから説明し直す必要 |
| 3. 分離 | エージェント間でコンテキストが孤立 | 片方が知る情報を他方が知らない |
メモリエンジニアリングとは何か
メモリエンジニアリングは、これらの課題に対する体系的な解決策として提唱されています。
定義:エージェントが過去の情報を適切に保持・検索・活用するための設計アプローチ
これは単なるRAG(検索拡張生成)を超えた、より広い概念です。4つのメモリ層を体系的に設計することで、ベクトル検索だけに頼らない多角的な情報管理を実現します。

4つのメモリタイプ
| メモリタイプ | 役割 | 具体例 |
|---|---|---|
| 短期記憶 | 進行中の会話やタスク | 現在の対話コンテキスト、作業中のコード |
| 長期記憶 | セッション横断的な永続化情報 | ユーザー設定、学習した好み |
| エピソード記憶 | 具体的な出来事の時系列記録 | 過去のプロジェクト経験、問題解決履歴 |
| 意味記憶 | 一般的知識やナレッジベース | ドメイン知識、ベストプラクティス |
なぜメモリエンジニアリングが「重要性判別」を可能にするのか
メモリエンジニアリングがベクトル検索の限界を超えられる理由は、多角的な情報検索・更新メカニズムにあります。
ベクトル検索 vs メモリエンジニアリング
| 観点 | ベクトル検索のみ | メモリエンジニアリング |
|---|---|---|
| 検索基準 | 意味的類似性のみ | 類似性+時間+重要度+関連性 |
| 情報の更新 | 静的(再インデックスが必要) | 動的(リアルタイム更新) |
| コンテキスト理解 | 現在のクエリのみ | 過去の経験・エピソードも考慮 |
| エージェント間共有 | 困難 | 設計段階から考慮 |

マルチエージェント時代の必然
メモリエンジニアリングが特に重要になるのは、マルチエージェント環境です。
コンテキストエンジニアリングだけでは、複数エージェント間で情報が自動共有されません。結果として:
- エージェントAが学んだことをエージェントBが知らない
- 同じ失敗を別のエージェントが繰り返す
- ユーザーが何度も同じ説明をする必要がある
ハイブリッドメモリアーキテクチャ
推奨されるのは、個別メモリ方式と共有メモリ方式のハイブリッド構成です。
- 個別メモリ:各エージェント固有の専門知識・経験
- 共有メモリ:プロジェクト情報・ユーザー設定など共通情報
- アクセス制御:誰が何を読み書きできるかの権限管理
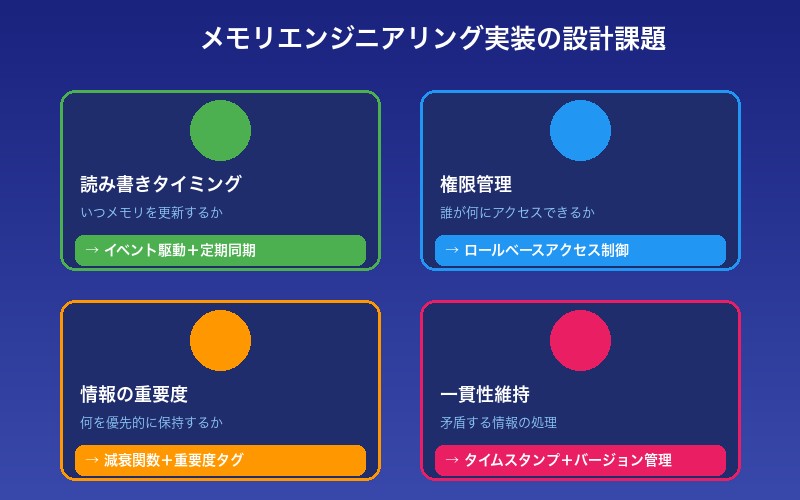
実装に向けた設計課題
メモリエンジニアリングを実装するには、いくつかの重要な設計課題を解決する必要があります。
| 設計課題 | 考慮事項 | 解決アプローチ |
|---|---|---|
| 読み書きタイミング | いつメモリを更新するか | イベント駆動+定期同期 |
| 権限管理 | 誰が何にアクセスできるか | ロールベースアクセス制御 |
| 情報の重要度 | 何を優先的に保持するか | 減衰関数+明示的な重要度タグ |
| 一貫性維持 | 矛盾する情報の処理 | タイムスタンプ+バージョン管理 |
Sam Altmanも認める「メモリ」の重要性
OpenAIのSam Altmanも、AIの次のブレークスルーについて「推論能力よりもメモリが鍵」だと発言しています。
現在のAIは「毎回ゼロから始める」という根本的な制約があります。人間のように過去の経験から学び、重要な情報を長期的に保持し、適切なタイミングで想起する—これがAIの次のステップです。
メモリエンジニアリングは、まさにこの課題に対する実践的なアプローチと言えます。
今後の展望:ベクトル検索を超えて
メモリエンジニアリングが普及すれば、以下のような変化が期待できます:
- パーソナライズの深化:ユーザーの好みや経験を長期的に学習
- エージェント間協調:チームとして機能するAIエージェント群
- 継続的学習:プロジェクトを通じた知識の蓄積
- 重要性の動的判断:文脈に応じた情報の優先順位付け
まとめ:次のAI革命の鍵
コンテキストエンジニアリングの課題—「情報の重要性をAIがうまく判別できない」—の根本原因は、ベクトル検索という単一の検索手法に依存していることにあります。
- ベクトル検索の限界:意味的類似性は捉えるが、重要性は判別できない
- コンテキストウィンドウ拡張の幻想:容量だけでは性能低下・揮発性・分離の問題は解決しない
- メモリエンジニアリング:4つのメモリ層による多角的な情報管理
- マルチエージェント対応:ハイブリッドメモリアーキテクチャで情報共有
ベクトル検索だけに頼らない、多角的な情報の取得・更新を可能にするメモリエンジニアリング。これこそが、AIエージェントの次の進化を支える鍵となるでしょう。
参考リンク:
コメント