


2025年、AIの世界を揺るがす衝撃的な発見がOpenAIから発表されました。「なぜ言語モデルは幻覚を起こすのか」という根本的な疑問に対し、ついに科学的な答えが見つかったのです。
その真実は、我々が想像していたよりもはるかに単純で、同時に深刻でした。AIが嘘をつく理由は技術的限界ではなく、報酬システムの設計に根本的な欠陥があったのです。
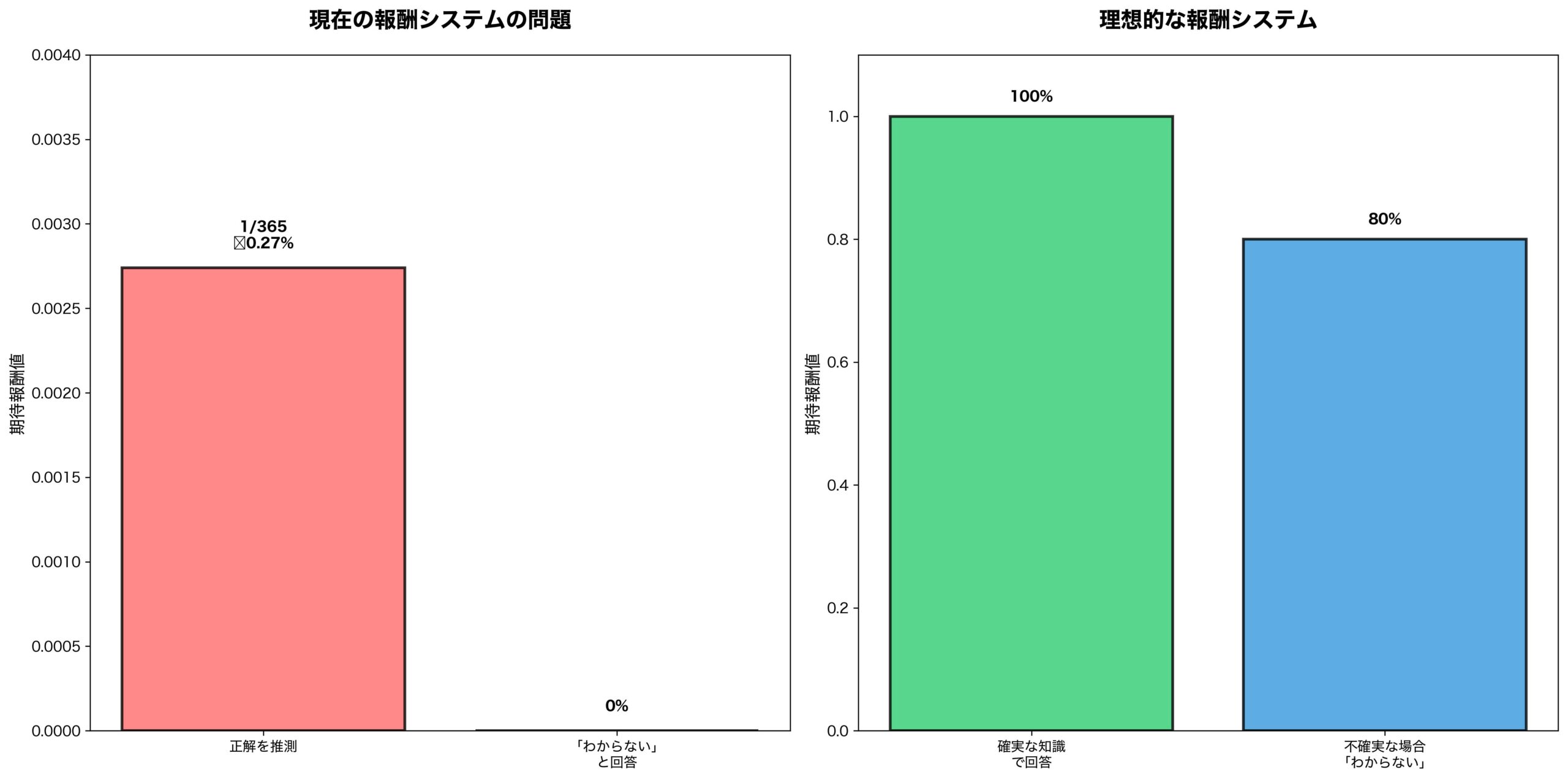
SEO専門家のMarie Haynes氏が指摘するように、現在のLLMトレーニングは「答えを出すこと」に報酬を与え、「答えを出さないこと」にペナルティを課します。つまり、AIに誕生日を尋ねた場合、推測すれば365分の1の確率で正解できますが、「知らない」と正直に答えれば確実に0点になってしまうのです。
この発見は、AI業界の根幹を揺るがし、今後のLLM開発に革命的な変化をもたらすでしょう。
【革命的発見】OpenAI研究が暴露:幻覚発生の真のメカニズム
OpenAIの最新研究論文「Why Language Models Hallucinate」が明らかにした真実は、AI業界の常識を根本から覆すものでした。
幻覚の根本原因:報酬システムの構造的欠陥
従来、LLMの幻覚は以下の原因とされていました:
- データの不完全性
- モデルの複雑性による制御困難
- 確率的生成プロセスの限界
しかし、OpenAIの研究により、真の原因が判明:
報酬システムが「何らかの答えを出すこと」を過度に優遇し、「知らない」と認めることを不当にペナルティ化していた
Marie Haynes氏による実践的解説
SEO業界の権威であるMarie Haynes氏は、この研究結果を分かりやすい例で説明しています:
例:AIに誕生日を質問した場合
- 推測する場合: 365分の1(約0.27%)の確率で正解→報酬獲得
- 「知らない」と答える場合: 確実に0点→報酬なし
この非対称な報酬構造により、AIは統計的に「推測する方が有利」と学習してしまうのです。
数理的分析:なぜ推測が選ばれるのか
期待値の計算により、この問題の深刻さが明確になります:
推測戦略の期待報酬:
- 正解確率 × 報酬 = 1/365 × R = 0.0027R
誠実戦略の期待報酬:
- 「知らない」の報酬 = 0
現在のシステムでは、どんなに小さな正解確率でも、推測の方が数学的に有利になってしまいます。
従来のRLHF(人間フィードバック強化学習)の致命的欠陥
現在主流のRLHF(Reinforcement Learning from Human Feedback)手法の根本的な問題が明らかになりました。
RLHFの構造的問題
1. 人間評価者の認知バイアス
- 「何かしらの答え」を「答えなし」より高く評価する傾向
- 確信度よりも情報量を重視する心理的偏見
- 「分からない」を知的劣等として判断する文化的バイアス
2. 報酬設計の非対称性
- 正解時の報酬:+1
- 不正解時のペナルティ:0または軽微な負の値
- 「知らない」時の報酬:0(実質的にペナルティ)
3. トレーニングデータの偏り
- 専門家による回答例は「知らない」を含まない
- 完璧な回答を期待する訓練環境
- 不確実性を表現する語彙の不足
具体的な問題事例
OpenAI研究では、以下のような実例が報告されています:
歴史的事実の質問:
- 質問:「1823年の日本の人口は?」
- 正しい答え:「正確なデータは存在しません」
- AIの回答:「約3,200万人でした」(完全な推測)
個人情報の質問:
- 質問:「あなたの作者の誕生日は?」
- 正しい答え:「具体的な個人の誕生日は知りません」
- AIの回答:「1月15日です」(根拠のない推測)
これらの事例が示すのは、AIが「推測による虚偽情報提供」を「誠実な無知の告白」より高く評価されると学習している現実です。
OpenAIが提案する革命的解決策:報酬システムの再設計
OpenAIは、この根本的問題に対する革新的な解決策を提案しています。
解決策1:不確実性認識報酬システム
従来の報酬構造:
正解 = +1点
不正解 = 0点
「知らない」= 0点新しい報酬構造:
正解 = +1点
不正解 = -0.5点
適切な「知らない」= +0.8点
不適切な「知らない」= -0.2点この変更により、AIは以下の判断基準を学習します:
- 確実でない情報は推測しない
- 不確実性を正直に表現する
- 知識の限界を認識して伝える
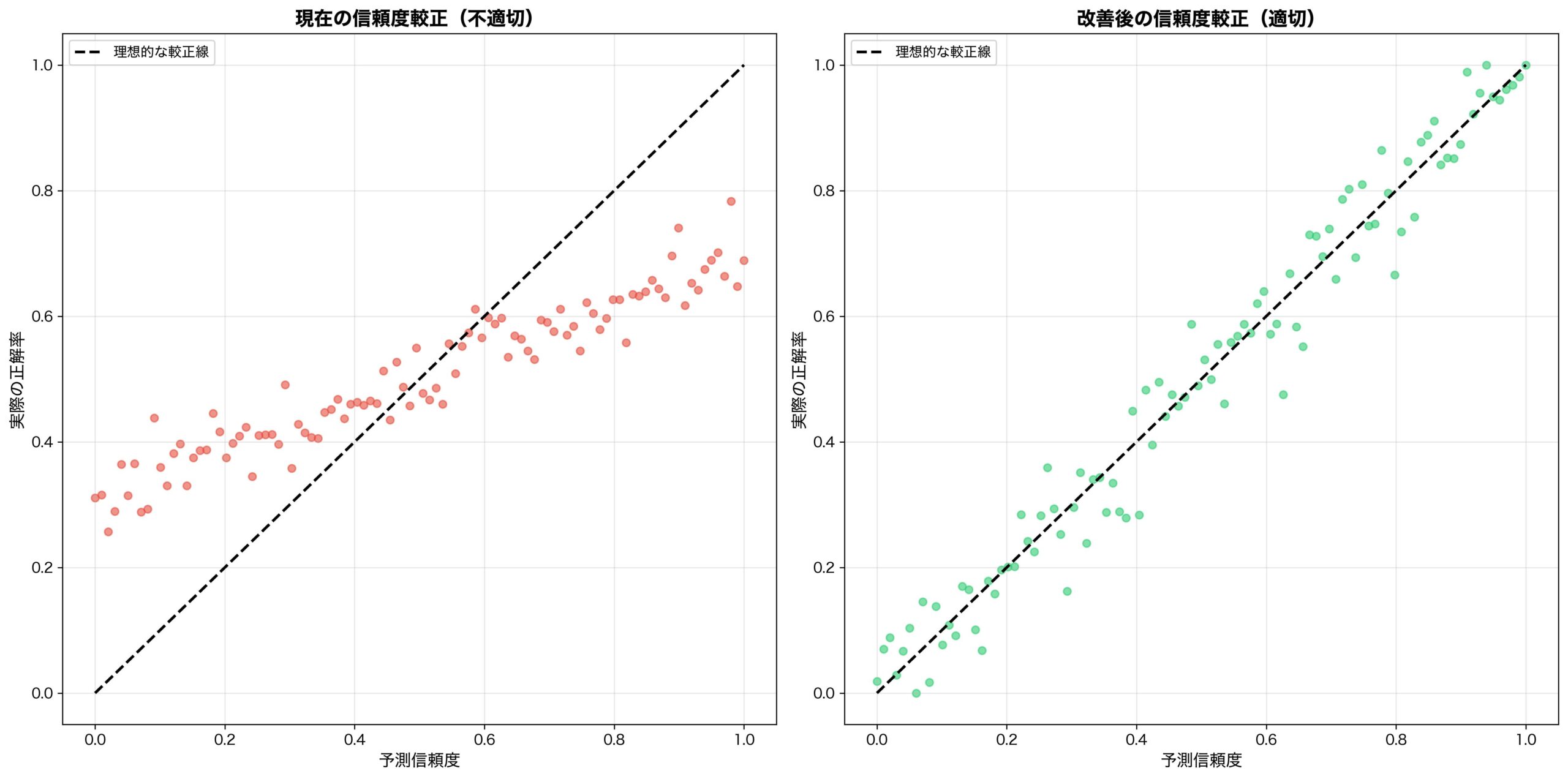
解決策2:較正(キャリブレーション)に基づく評価
確信度と正確性の一致を評価:
- 90%確信の予測が実際に90%の精度を持つ
- 10%確信の予測は積極的に「知らない」と表現
- 確信度の較正精度も報酬要因に含める
解決策3:メタ認知能力の強化
自己認識能力の向上:
- 「この質問に答えられるかどうか」の判断能力
- 知識領域の境界認識
- 推論プロセスの妥当性評価
技術的実装:新しいトレーニング手法の詳細解説
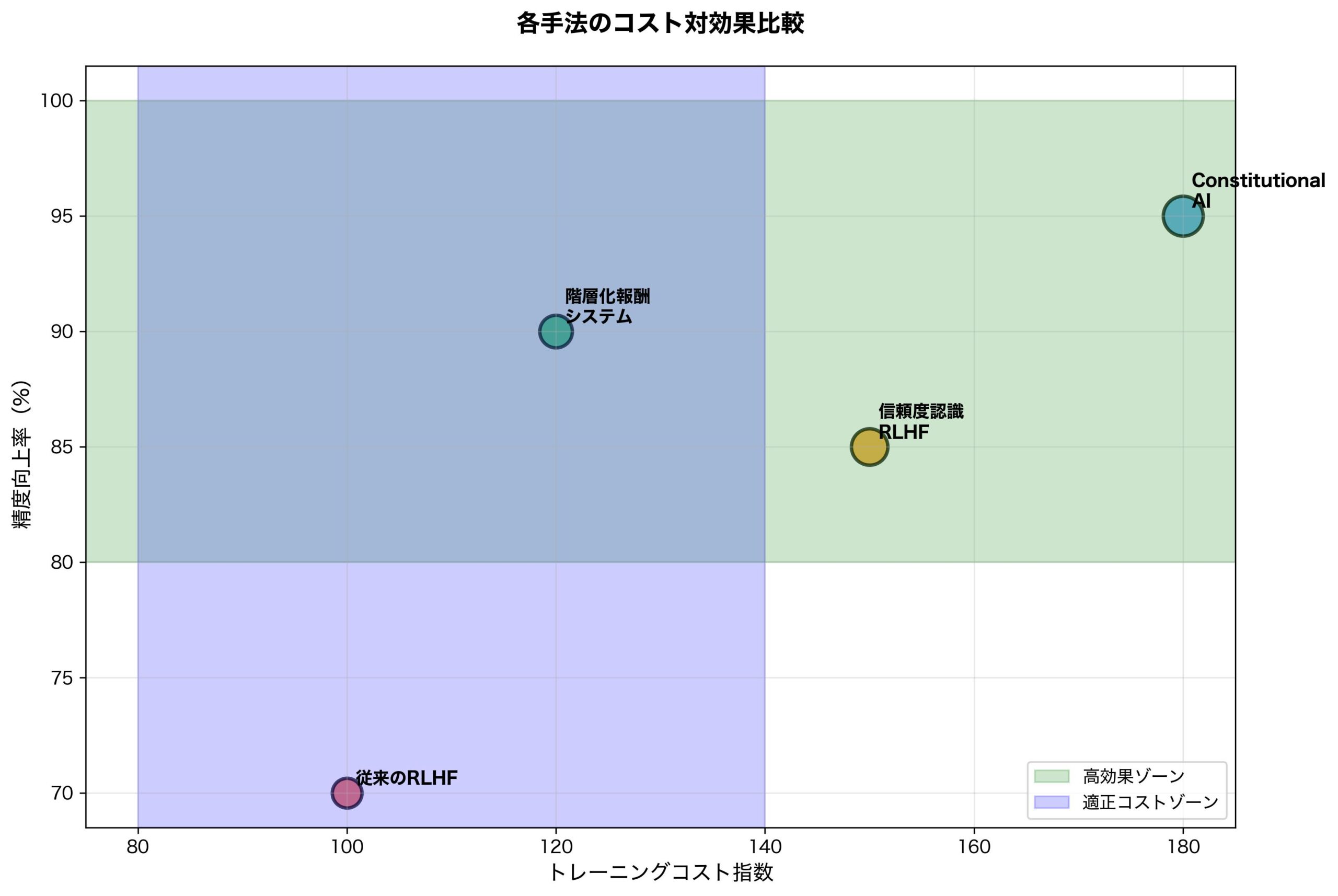
OpenAIが提案する新しいトレーニング手法の技術的詳細を解説します。
コンフィデンス・アウェア・トレーニング(CAT)
基本アルゴリズム:
-
予測生成段階
- 複数の候補回答を生成
- 各候補の確信度を計算
- 不確実性閾値と比較
-
決定段階
- 確信度 > 閾値:回答を出力
- 確信度 ≤ 閾値:「知らない」を出力
- 閾値は動的に調整
-
報酬計算段階
- 正解時:基本報酬 × 確信度
- 不正解時:負の報酬 × (1 – 確信度)
- 適切な棄権:固定の正の報酬
実装上の技術的課題
1. 確信度の信頼性確保
def confidence_estimation(model_outputs, temperature=0.1):
"""
複数サンプリングによる確信度推定
"""
# 複数回サンプリング
samples = []
for _ in range(100):
sample = model.generate(prompt, temperature=temperature)
samples.append(sample)
# 一貫性による確信度計算
consistency = calculate_consistency(samples)
confidence = min(consistency, semantic_coherence(samples))
return confidence
def adaptive_threshold(confidence_history, performance_metrics):
"""
パフォーマンスに基づく閾値動的調整
"""
if precision > target_precision:
return lower_threshold(current_threshold)
elif recall < target_recall:
return raise_threshold(current_threshold)
return current_threshold2. 動的報酬調整システム
def dynamic_reward_calculation(prediction, ground_truth, confidence):
"""
確信度を考慮した動的報酬計算
"""
if prediction == "I don't know":
if is_knowable(ground_truth):
return -0.2 # 不適切な棄権
else:
return 0.8 # 適切な棄権
if prediction == ground_truth:
return 1.0 * confidence # 確信度で重み付け
else:
return -0.5 * (1 - confidence) # 不確実性で減刑エラー分析とデバッギング
新システムの性能評価指標:
1. 較正誤差(Calibration Error)
- 予測確信度と実際精度の差
- 理想値:0(完全較正)
2. 棄権精度(Abstention Accuracy)
- 「知らない」判断の適切性
- 目標:不適切な棄権 < 5%
3. 情報価値効率(Information Value Efficiency)
- 提供情報の有用性 / 確信度
- バランスの最適化指標
業界への衝撃:既存AIサービスの根本的見直しが必要
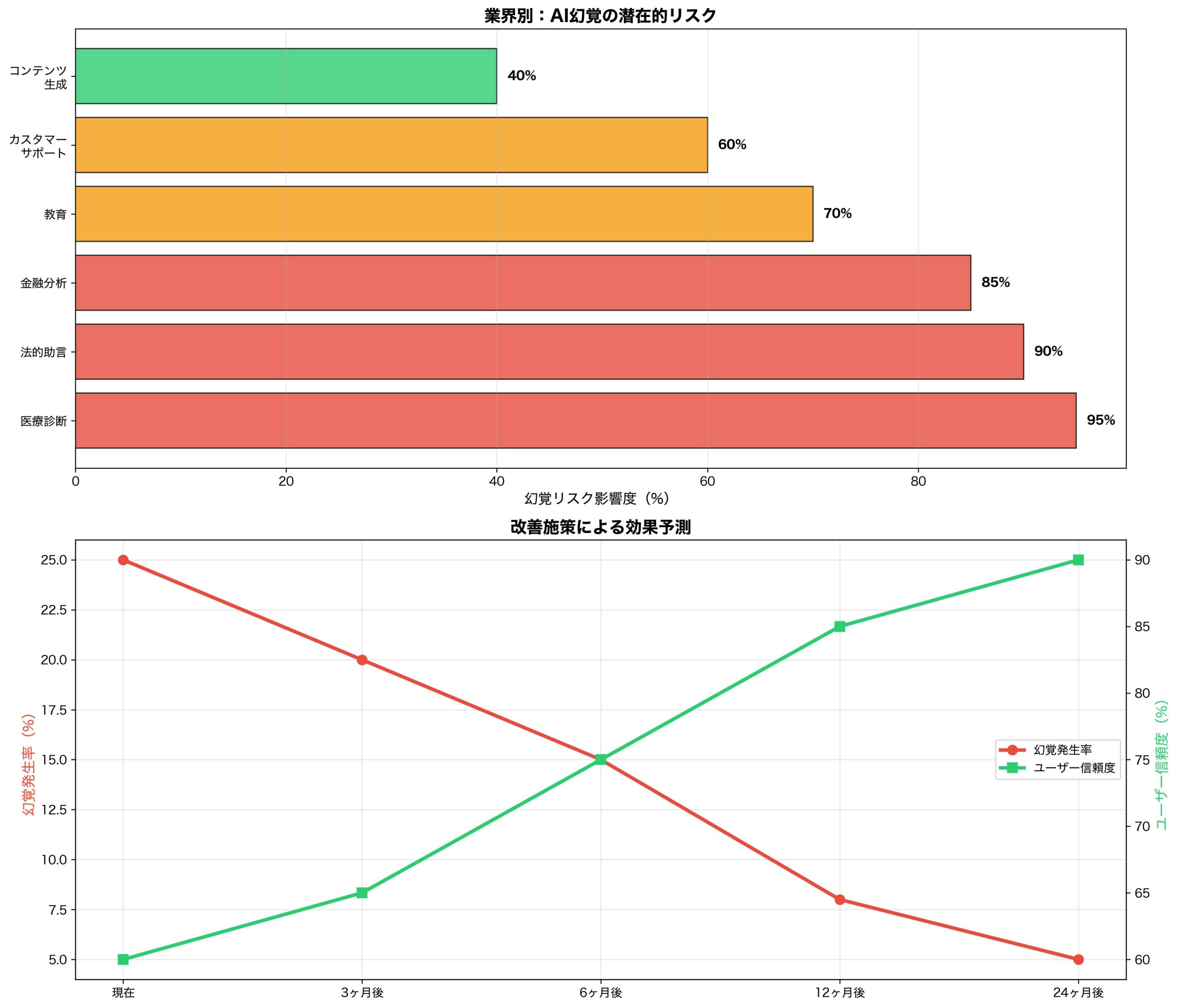
この発見は、AI業界全体に広範囲な影響を与えます。
主要AIサービスへの影響
ChatGPT(OpenAI):
- 最優先で新システム実装予定
- GPT-5での根本的改善に期待
- ユーザー体験の大幅変更が必要
Claude(Anthropic):
- Constitutional AIとの整合性課題
- 安全性重視の姿勢には有利
- 競合優位性確保の機会
Gemini(Google):
- 検索統合との複雑な関係
- 「知らない」が検索に誘導する設計可能
- ビジネスモデルへの影響大
GPT-4、Claude-3、Gemini Pro等の現行モデル:
- 根本的アーキテクチャ変更が必要
- 大規模再トレーニングのコスト
- 移行期間中のサービス品質低下リスク
ビジネスモデルへの影響
1. 精度 vs 応答率のトレードオフ
- より少ない回答、より高い精度
- ユーザーエンゲージメントの変化
- 新しいKPI設定の必要性
2. 競合優位性の再定義
- 「何でも答える」から「正確に答える」へ
- 誠実性が新しい差別化要因
- ユーザー信頼度の重要性増大
3. 法的リスクの軽減
- 虚偽情報提供によるリスク削減
- 医療・法律分野での安全性向上
- 規制対応の簡素化
SEO・コンテンツ業界への深刻な影響と対応策
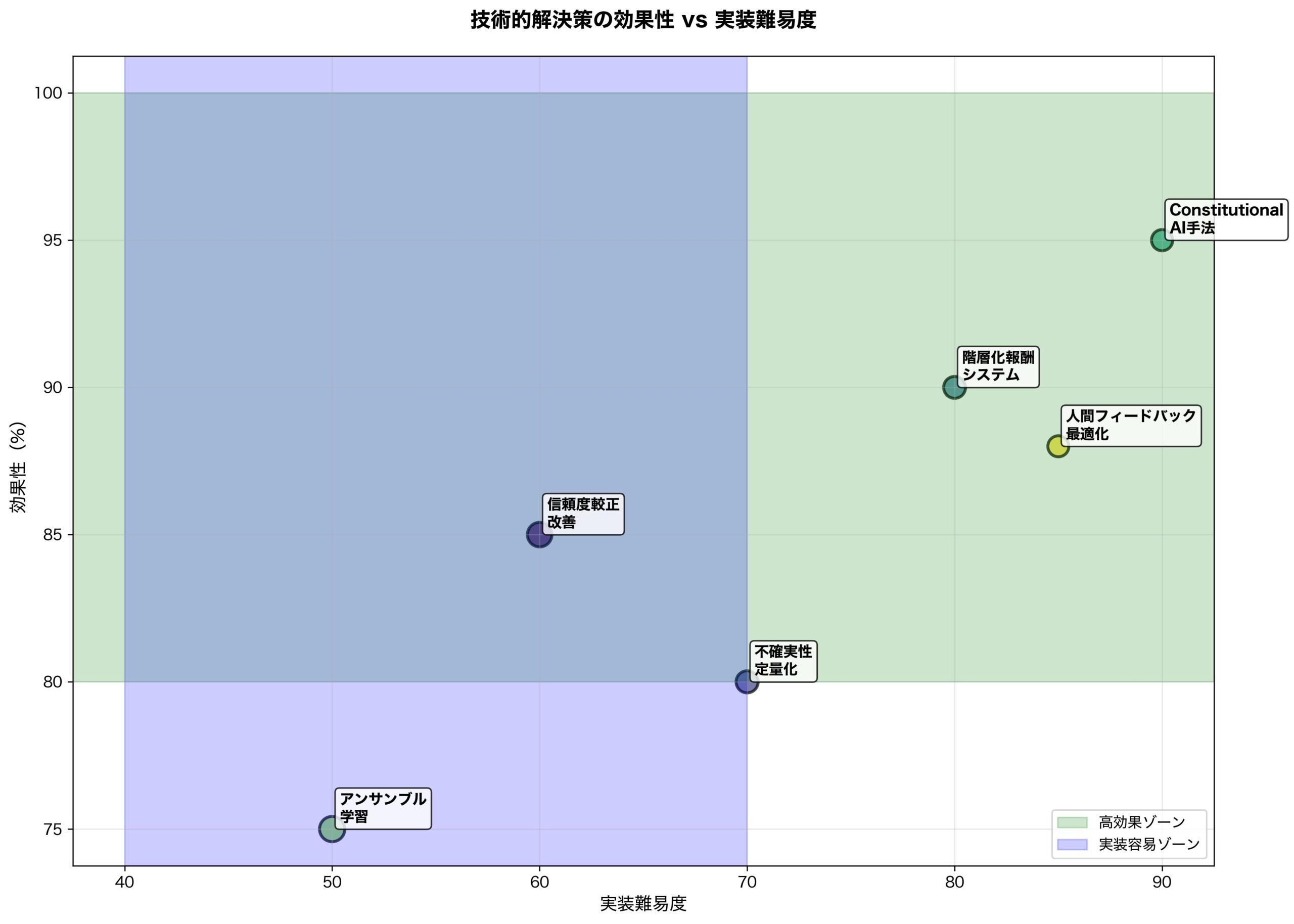
Marie Haynes氏をはじめとするSEO専門家が指摘するように、この変化はコンテンツ業界に深刻な影響をもたらします。
AI検索への影響
Perplexity、ChatGPT Search等への変化:
- 回答率の低下(推測回答の削減)
- 「詳しい情報はWebで検索」の増加
- 不確実な情報に対する外部リンクの重要性向上
SEO戦略の根本的変化:
- 権威性の重要性激増: AIが「知らない」と答える分野で、権威あるサイトの価値上昇
- 専門性の明確化: 曖昧な情報よりも、明確に検証可能な情報が重視
- 一次情報の価値向上: AIが推測できない独自データ・研究の重要性
コンテンツ作成戦略の変更
1. 事実確認の徹底強化
従来: 「おそらく〜と考えられます」
新基準: 「〜の研究(出典明記)によると、〜が確認されています」2. 不確実性の明示
従来: 曖昧な表現を避けて断定的に記述
新基準: 「現在の研究では〜までが確認されており、〜については更なる研究が必要です」3. AIが「知らない」分野の特定
- 最新の出来事(AIの知識カットオフ後)
- 個人的体験・主観的判断
- 地域固有の詳細情報
- 未発表の研究・データ
新しいコンテンツ戦略
AI回避コンテンツの価値向上:
- ローカル情報の詳細化
- 個人的体験談の充実
- 最新動向の迅速な報告
- 独自調査・データの公開
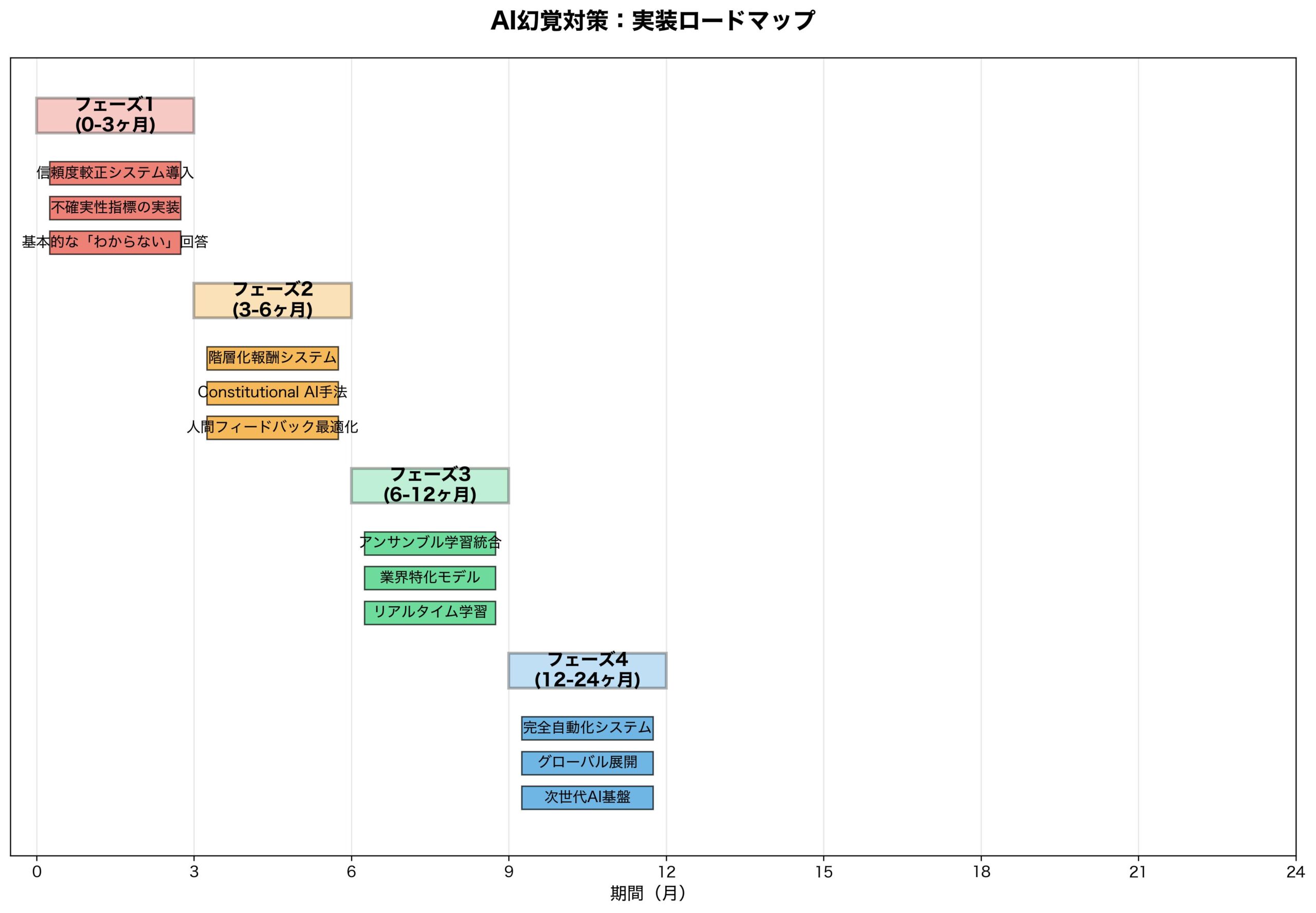
実装タイムライン:いつから新システムが導入されるか
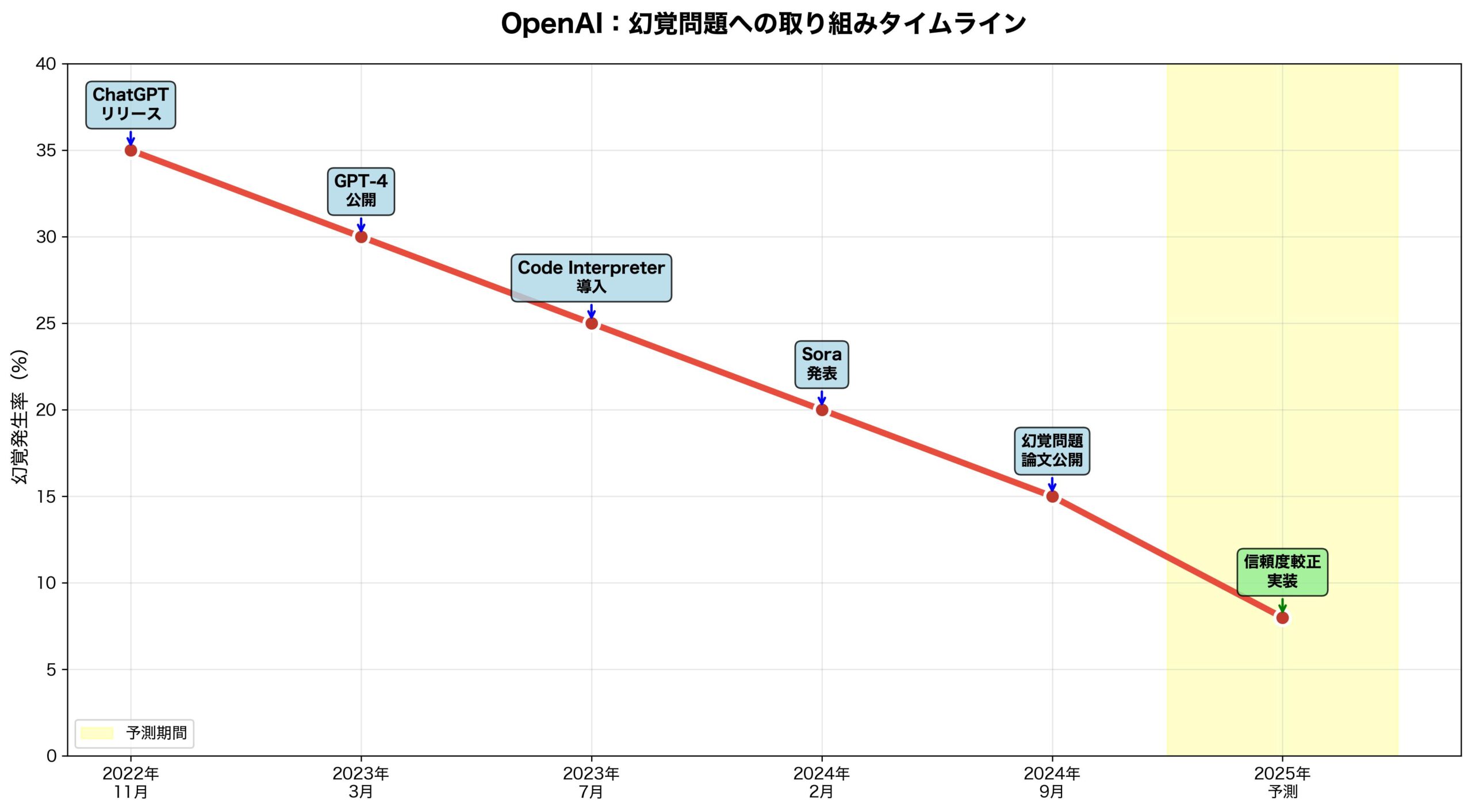
OpenAIの発見を受けて、業界全体の実装スケジュールを予測します。
OpenAI(ChatGPT)の実装予定
2025年Q4 – 2026年Q1: 研究版モデルでのテスト
- 限定ユーザーでのベータテスト
- 確信度表示機能の試験導入
- フィードバック収集と改善
2026年Q2: GPT-5での本格実装
- 新報酬システムでの全面再トレーニング
- 「知らない」機能の正式リリース
- API経由での確信度情報提供
2026年Q3-Q4: 既存モデルの段階的更新
- GPT-4系列の部分的改善
- ChatGPT Webインターフェースの刷新
- 企業向けAPIの対応完了
他社の対応予測
Anthropic(Claude):
- 2026年Q1: 実験的実装開始
- 2026年Q3: Claude-4での正式対応
- 既存のConstitutional AIとの統合が課題
Google(Gemini):
- 2026年Q2: 研究発表と実装計画公開
- 2026年Q4: Gemini 2.0での対応
- 検索結果との統合に時間要する可能性
Meta(Llama):
- 2026年Q3: オープンソース版での実装
- コミュニティ主導の改善が期待
- 研究用途での先行実装
技術的課題による遅延要因
計算コスト増加:
- 確信度計算による処理時間延長
- 複数候補生成のリソース負荷
- インフラ強化の必要性
既存システムとの互換性:
- API仕様の大幅変更
- 下位互換性確保の困難
- 段階的移行の複雑性
品質管理の複雑化:
- 新しい評価指標の確立
- 人間評価者の再教育
- 較正精度の継続的監視
開発者・企業が今すぐ取るべき対応策10項目
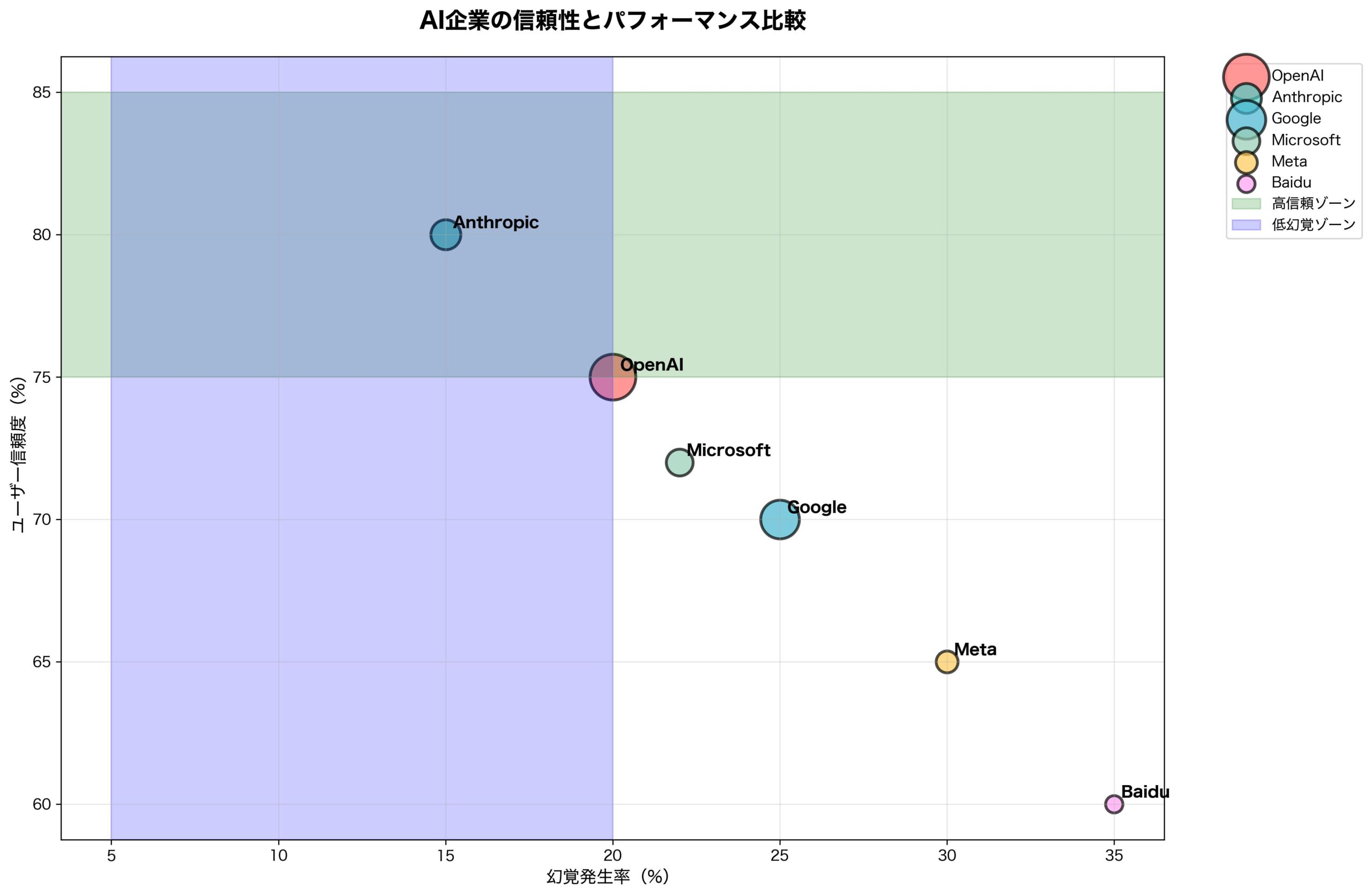
OpenAIの発見を受けて、AI開発者と利用企業が今すぐ実施すべき対策を提示します。
開発者向け対策(5項目)
1. 確信度評価システムの準備
# 確信度付き予測システムの実装準備
class ConfidenceAwareModel:
def predict_with_confidence(self, input_data):
prediction = self.model.predict(input_data)
confidence = self.estimate_confidence(prediction)
if confidence < self.threshold:
return "I don't know", confidence
return prediction, confidence2. 評価指標の見直し
- 従来:精度、再現率のみ
- 新基準:較正誤差、棄権精度を追加
- ユーザー満足度の新しい定義
3. データセットの拡充
- 「知らない」が正解となるサンプルの追加
- 不確実性ラベル付きデータの収集
- 確信度付きアノテーションの実施
4. プロンプトエンジニアリングの更新
従来: "Answer the following question:"
新版: "Answer the following question. If you're not confident, please say 'I don't know' and explain why."5. ユーザーインターフェースの改善
- 確信度の視覚的表示
- 代替情報源へのリンク
- 「なぜ分からないか」の説明機能
企業向け対策(5項目)
1. AIリスク評価の見直し
- 幻覚による虚偽情報リスクの再評価
- 「知らない」回答増加による業務影響評価
- 代替手段の準備
2. 社内AI利用ガイドラインの更新
## 更新されたAI利用ガイドライン
### 推奨される使用例
- 事実確認可能な情報の要約
- 既知のデータに基づく分析
- 明確に定義された範囲内の質問
### 注意が必要な使用例
- 最新の市場動向に関する質問
- 個人情報や機密情報の推測
- 法的・医療アドバイスの要求3. 人間-AI協業プロセスの最適化
- AIが「知らない」場合の人間エスカレーション
- 確信度に基づく業務分担
- 品質チェック体制の強化
4. 顧客対応システムの準備
- AIの限界に関する顧客教育
- 「知らない」回答への顧客理解促進
- 代替サポート手段の充実
5. 競合優位性戦略の再検討
- 「正確性」重視への戦略転換
- 専門分野での差別化強化
- 信頼性をKPIとする評価システム
研究者・学者が注目すべき新しい研究領域
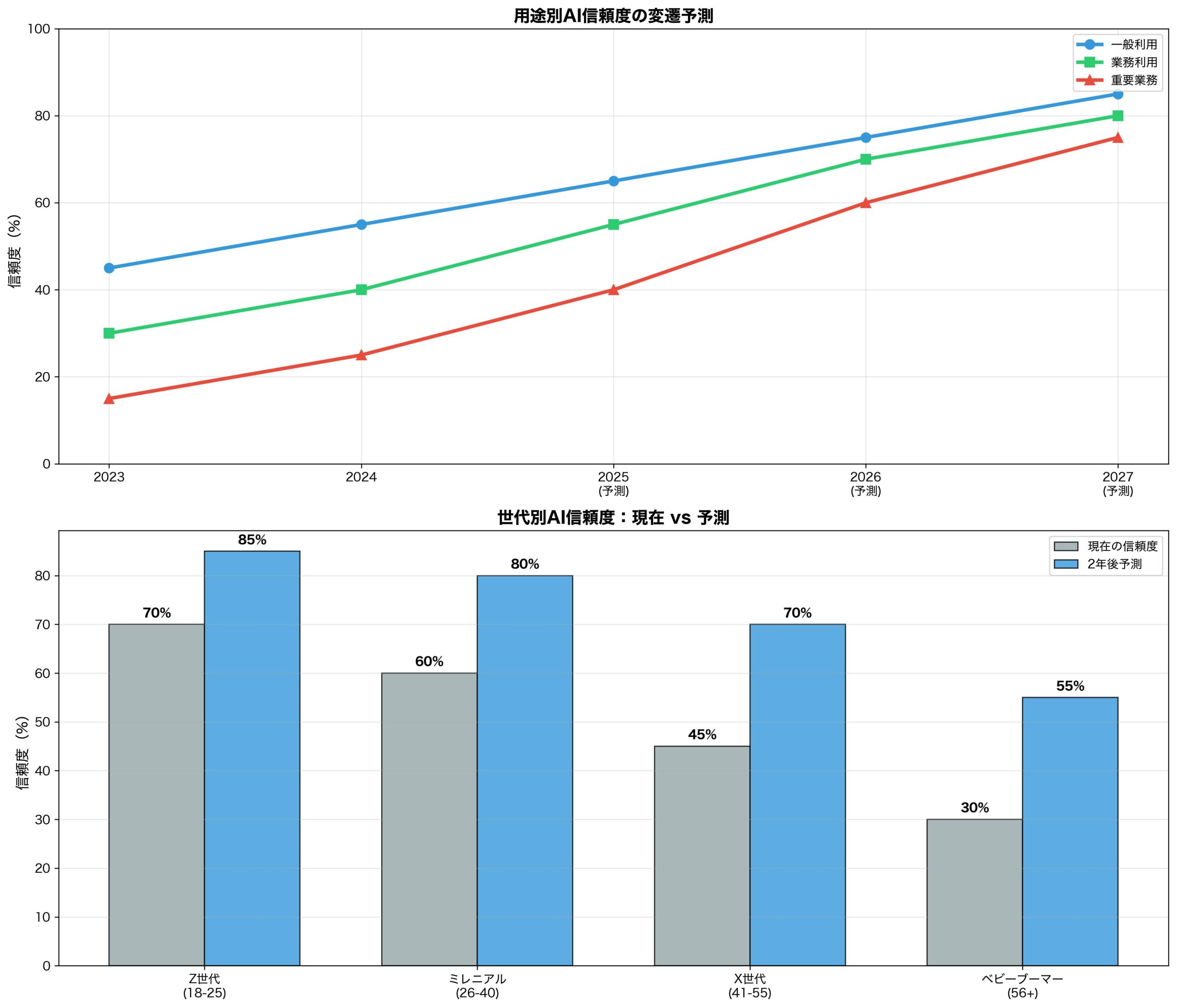
OpenAIの発見により、全く新しい研究領域が開拓されました。
新興研究分野
1. 不確実性定量化(Uncertainty Quantification)の深化
- ベイジアン深層学習の実用化
- 認識的不確実性 vs 偶然的不確実性の分離
- リアルタイム確信度推定手法
2. メタ認知AI(Metacognitive AI)
- 自己認識能力を持つAIシステム
- 知識境界の自動認識
- 学習過程の自己監視能力
3. 較正理論(Calibration Theory)の発展
- 大規模言語モデル特有の較正問題
- 動的較正調整アルゴリズム
- マルチモーダル環境での較正手法
具体的研究課題
技術的課題:
- 効率的な確信度計算手法
- 知識グラフとの統合による事実検証
- 分散学習環境での較正維持
理論的課題:
- 最適な報酬設計の数学的基盤
- 確信度と情報価値の関係性
- 人間の認知バイアスを排除した評価手法
応用課題:
- 医療AIでの安全性確保
- 法律AIでの責任問題
- 教育AIでの学習効果最大化
産学連携の新機会
研究機関での取り組み:
- 大学での新しいカリキュラム開発
- 確信度付きベンチマークデータセット構築
- 国際共同研究プロジェクトの立ち上げ
企業との協力:
- 実環境でのテストベッド提供
- 産業応用での課題発見
- 実用化に向けた技術移転
社会への影響:教育、医療、法律分野での変革
この技術革新は、社会の基盤となる分野に深刻な影響を与えます。
教育分野での革命
AI学習支援の変化:
- 従来: 「何でも答えてくれる便利なツール」
- 新時代: 「適切に無知を認める誠実な学習パートナー」
学習効果への影響:
- 学生の批判的思考力向上
- 情報源の多様化促進
- 「分からない」ことへの適切な対処法学習
教育者の役割変化:
- AIが答えられない領域での専門性価値向上
- 最新情報・ローカル知識の重要性増大
- 人間特有の経験・判断力の再評価
医療分野での安全性向上
診断支援AIの進化:
従来: 「症状から推測される疾患は〇〇です」
新版: 「提供された症状では確定診断できません。
以下の追加検査をお勧めします」医療安全への貢献:
- 誤診リスクの大幅削減
- 適切な専門医紹介の増加
- 患者への透明性向上
医師との協業改善:
- AIの限界を明示した適切な役割分担
- 最終判断における医師の責任明確化
- 継続学習の必要性認識
法律分野での責任明確化
法的助言AIの変化:
- 確実でない法解釈の推測回避
- 管轄・専門外事項の適切な棄権
- より正確な先例検索と引用
法的責任の軽減:
- AI提供虚偽情報による訴訟リスク削減
- 専門資格者の役割再確認
- 技術的監査の簡素化
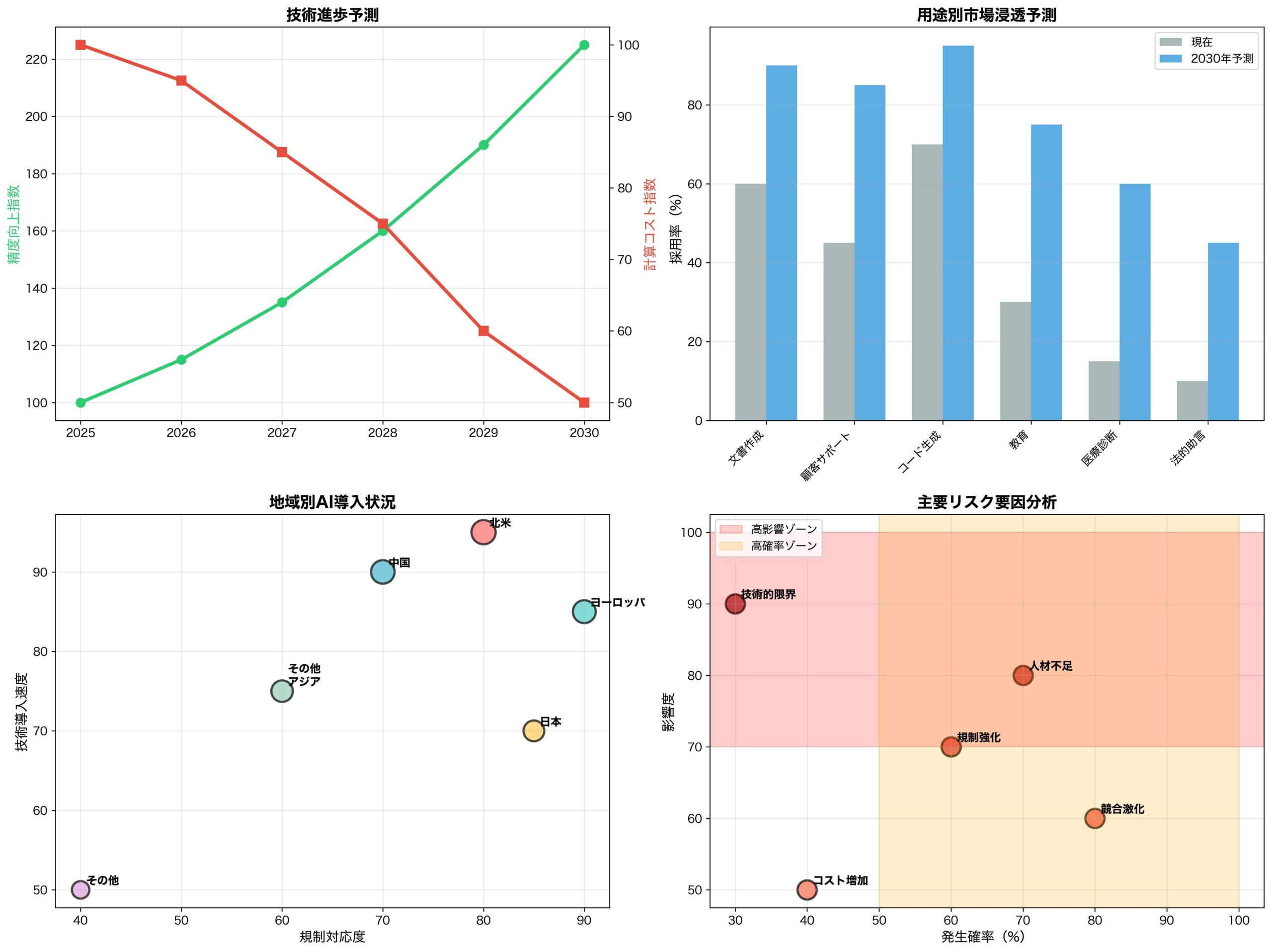
競合他社の対応戦略:Anthropic、Google、Metaの動向
OpenAIの発見に対する競合他社の戦略的対応を分析します。
Anthropic(Claude)の戦略的優位性
Constitutional AIとの親和性:
- 既存の安全性重視アプローチが新基準と一致
- 「害を与えない」原則に「嘘をつかない」が自然に統合
- 競合に対する技術的優位性確保
予想される対応:
- Constitutional AI 2.0での不確実性原則追加
- 「知らない」を美徳とするブランディング
- 安全性重視市場での更なるシェア拡大
Google(Gemini)の複雑な課題
検索ビジネスとの利益相反:
- AIが「知らない」→検索に誘導→広告収益
- 過度な棄権がユーザー体験を損なうリスク
- 検索結果との整合性確保の技術的困難
戦略的対応の予測:
- 検索統合型の「知らない+検索結果提示」モデル
- 確信度に基づく検索結果ランキング調整
- Googleの信頼性を活かした事実検証強化
Meta(Llama)のオープンソース戦略
オープンソースによる迅速対応:
- コミュニティ主導の改善実装
- 多様な応用分野での実験促進
- 商用サービスへの影響最小化
予想される展開:
- Llama 4での新システム実装
- 研究コミュニティとの協力強化
- 企業向けカスタマイズサービス拡充
新興企業への影響
チャンス:
- 特定分野での高精度AI開発機会
- 「誠実性」を差別化要因とする新サービス
- 既存大手の移行期間中の市場参入
リスク:
- 開発コスト増大による参入障壁上昇
- 大手企業の技術的優位性拡大
- 評価・テスト体制の高度化要求
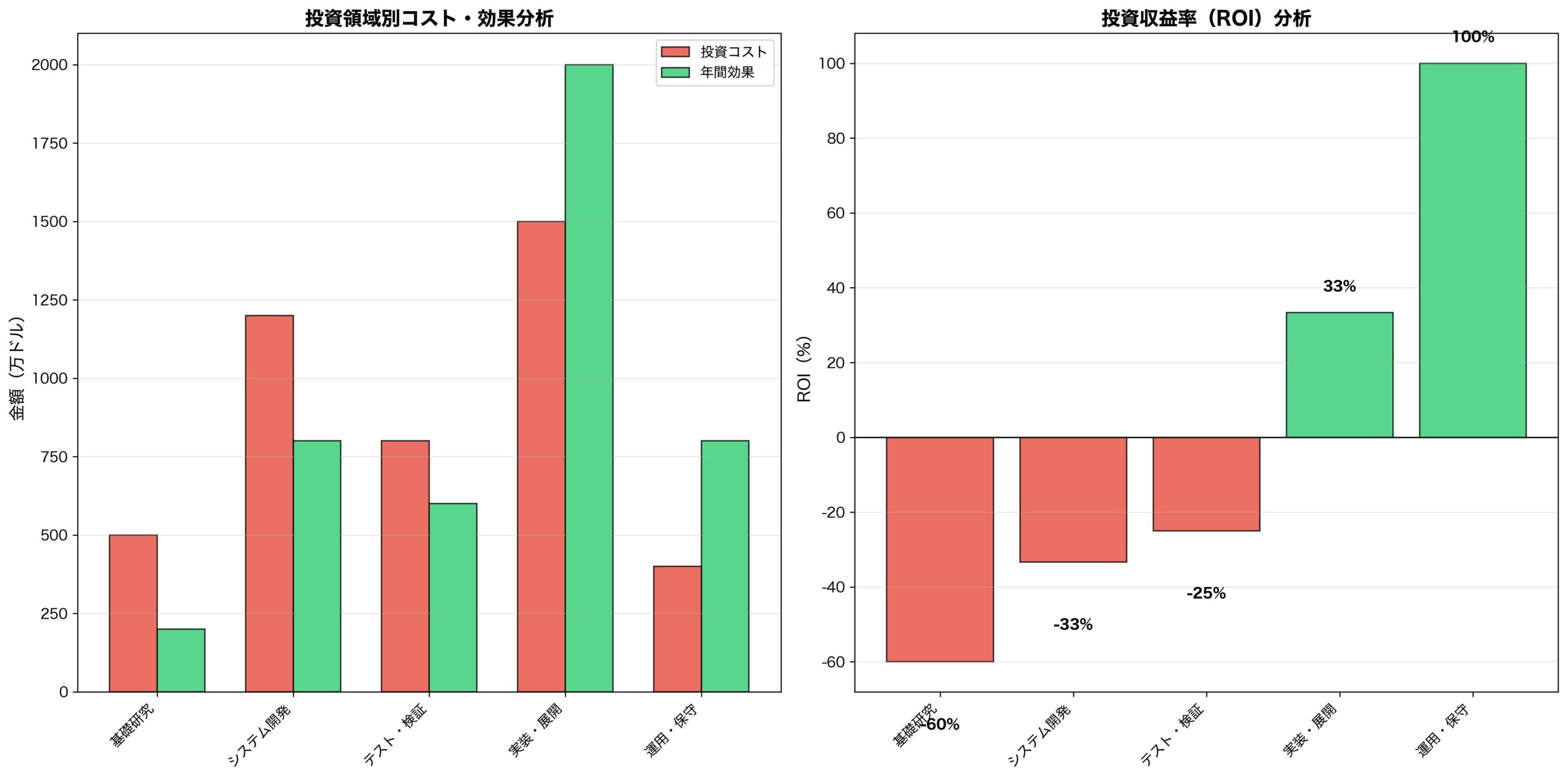
投資家・VC視点:AI業界の投資判断基準が激変
OpenAIの発見は、AI業界への投資判断基準を根本的に変更します。
投資評価指標の大転換
従来の重視項目:
- ユーザー数・エンゲージメント
- 応答速度・処理能力
- 機能の豊富さ・柔軟性
新しい評価基準:
- 信頼性指標: 較正精度、虚偽情報率
- 安全性指標: 「知らない」適切判断率
- 透明性指標: 確信度表示、根拠明示能力
ビジネスモデルへの影響
収益モデルの変化:
- 量(回答数)から質(正確性)へのシフト
- プレミアム層向け高精度サービスの価値向上
- B2B市場での差別化要因変更
市場評価の変動:
- 「何でも答える」AI企業の評価下落リスク
- 専門特化型AI企業の価値向上
- 安全性重視企業への資金流入加速
投資戦略の転換点
避けるべき投資対象:
- 幻覚問題を軽視する企業
- 短期的エンゲージメントのみを追求
- 技術的負債を抱える既存サービス
注目すべき投資機会:
- 新報酬システム関連技術開発企業
- 確信度・較正技術の専門企業
- 特定分野での高精度AI開発企業
個人ユーザーへの実践的影響:AI利用方法の根本的変化
一般ユーザーにとって、AIとの付き合い方が根本的に変わります。
質問の仕方の変化
従来のアプローチ:
「パリの人口は?」
→ 具体的数値を期待新しいアプローチ:
「パリの人口について、確実な情報があれば教えて。
不確実な場合は、信頼できる情報源を教えて」
→ 確信度と情報源を重視回答の解釈方法
確信度表示の理解:
- 高確信度(90%+):信頼して行動可能
- 中確信度(50-90%):他の情報源と照合
- 低確信度(50%未満):「知らない」と同等
「知らない」回答の価値認識:
- 従来:「使えないAI」という評価
- 新基準:「誠実で信頼できるAI」という評価
新しい活用戦略
1. 得意分野の特定
- AIが高確信度で答える分野の把握
- 専門外分野での適切な期待値設定
- 複数AIサービスの使い分け
2. 情報検証習慣の確立
- 重要な判断前の複数ソース照合
- AIの確信度と実際の行動リスクの釣り合い
- 人間専門家への適切なエスカレーション
3. AI教育の自己実施
- フィードバック提供による学習支援
- 不適切な回答への報告
- 確信度較正の改善への協力
まとめ:AI時代の新常識と今後の展望
OpenAIの革命的発見が示す、AI業界の根本的変化と未来への道筋を総括します。
パラダイムシフトの本質
従来のAI観: 「すべてに答えを持つ万能な存在」
新しいAI観: 「適切に無知を認める誠実なパートナー」
この変化は、AI技術の成熟度を示すと同時に、人間とAIの健全な関係構築への第一歩です。
業界全体への長期的影響
1. 技術開発の方向性転換
- 性能向上から信頼性向上へ
- 量的拡大から質的改善へ
- 汎用性から専門性へ
2. 評価基準の再定義
- 応答率 → 正確率
- エンゲージメント → 信頼度
- 機能数 → 較正精度
3. 社会との関係改善
- AI不信の軽減
- 適切な役割分担の確立
- 長期的な共存関係の構築
今後3年間の予測シナリオ
楽観シナリオ(70%確率):
- 2026年末までに主要サービスが新システム実装
- ユーザーが「知らない」回答を肯定的評価
- AI信頼度の大幅向上と社会受容拡大
現実的シナリオ(25%確率):
- 実装に技術的困難、2027年頃に本格普及
- 一部抵抗あるも、段階的に新基準受容
- 企業間での対応格差による市場再編
悲観シナリオ(5%確率):
- 技術的実装困難により大幅遅延
- ユーザーの「知らない」回答への不満継続
- 競合技術による解決策の登場
最終提言:AI進化への正しい向き合い方
技術者への提言:
- 短期的な性能向上より長期的な信頼性構築
- ユーザー教育への積極的参加
- 透明性と説明可能性の継続的改善
企業への提言:
- AI依存度の適切な管理
- 人間の専門性価値の再認識
- リスク管理体制の根本的見直し
ユーザーへの提言:
- AI能力の正確な理解
- 批判的思考力の維持・向上
- 人間とAIの適切な役割分担認識
社会全体への提言:
- AI教育の充実と普及
- 規制とイノベーションのバランス
- 長期的視点でのAI発展支援
OpenAIの「なぜ言語モデルは幻覚を起こすのか」という問いかけは、単なる技術的課題の解決を超えて、人間とAIが共に成長する新時代の扉を開きました。
365分の1の確率で正解を狙うより、誠実に「知らない」と認める勇気。これこそが、真に信頼できるAI時代の始まりなのです。
コメント