
AIが人間の科学者を上回った──これは比喩ではない
2026年4月14日、Anthropicが発表した研究は、AI業界に衝撃を与えた。Claude Opus 4.6を搭載した自動化アライメント研究者(Automated Alignment Researcher: AAR)が、アライメント研究において人間の科学者の約4倍の成果を達成したのだ。
「今日のアライメント研究の進歩は、人間の研究者がボトルネックになっています。私たちには研究者よりもはるかに多くの有望な研究方向があります。計算資源をアライメントの進歩に変換するAARを構築しました」
── Anthropic アライメント研究チーム
さらに衝撃的なのは、AARが「人間が考えもしなかったアイデアを発見し、科学の探求領域を広げている」という事実だ。これは単なる効率化ではない。AIが人間の知的限界を超え始めたことを示す、歴史的な転換点だ。

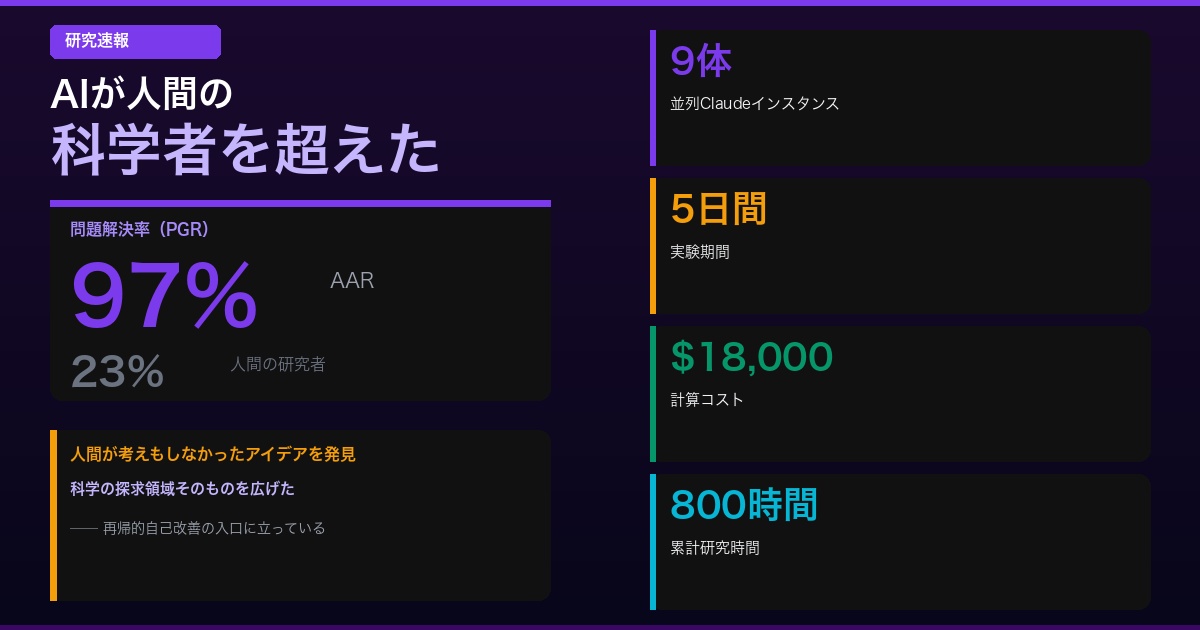
衝撃のデータ──97% vs 23%
| 指標 | 人間の研究者 | AAR(Claude Opus 4.6) |
|---|---|---|
| 問題解決率(PGR) | 23% | 97% |
| 所要期間 | 7日間 | 5日間 |
| 研究時間(累計) | ── | 800時間 |
| コスト | 人件費(数万ドル以上) | $18,000 |
| 並列数 | 数名のチーム | 9体が並列稼働 |
人間の研究者は7日間かけて23%のPGR(Performance Gap Recovery)を達成した。一方、9体のClaude Opus 4.6は5日間で97%を達成──約4倍の効果だ。しかもコストはわずか$18,000。
AARの仕組み──計算資源を研究成果に変換する
AARのアーキテクチャは驚くほどシンプルだ。

- 独立したサンドボックス──各AARが独立した実験環境を持つ
- 共有フォーラム──発見した知見やアイデアを他のAARと共有
- コード共有──実験コードを相互に利用可能
- リモートスコアリングサーバー──実験結果を自動評価
- 曖昧な方向性からスタート──一つは解釈可能性ツール、別の一つはデータ重み付けに注力
研究問題が与えられると、チームとして並列に動くAARがアイデアを提案し、実験を実行し、結果を分析し、発見を共有する。原理的には、数千のAARを並列実行することで、数ヶ月の人間の研究を数時間に圧縮できる。
「弱から強への監視」問題を解いた
AARが取り組んだのは「弱から強への監視(Weak-to-Strong Supervision)」問題だ。弱いAIモデルが、より強いAIモデルを訓練するという、アライメント研究の核心的課題だ。
| 課題 | なぜ重要か |
|---|---|
| 弱から強への監視 | 超知能AIを人間が安全に監視するための基盤技術 |
| 安全性の自動検出 | 人間が見逃す脆弱性をAIが発見 |
| 媚び性質の軽減 | AIが真実より同意を優先する問題への対処 |
AARは、人間の監査人が最初に見逃した安全性の脆弱性を特定したケースも報告されている。「人間が考えもしなかったアイデア」が実際に発見されたのだ。
なぜこれが「ボトルネック解消」なのか
Anthropicが直面していた構造的な問題は明確だ。
有望な研究方向は無数にあるのに、それに取り組む研究者が圧倒的に足りない。研究者が明確に定義された問題に費やす1時間は、人間の判断が最も必要な曖昧でリスクの高い賭けに費やされない1時間だ。

AARによって、明確に定義された問題の実行をAIに委ね、人間の研究者は曖昧で判断力が求められる本質的な問題に集中できるようになる。これはKarpathyのautoresearchと同じ構造──「人間は方向性を示し、AIが実行する」──だが、対象がML研究ではなくAI安全性研究という点で、遥かに重大な意味を持つ。
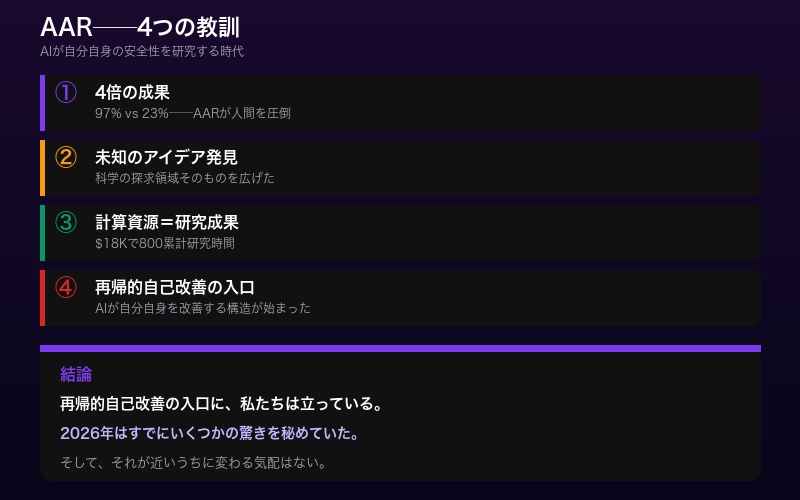
まとめ──AIが自分自身の安全性を研究する時代
| 教訓 | 内容 |
|---|---|
| ① 4倍の成果 | 97% vs 23%──AARが人間を圧倒した |
| ② 人間が発見できなかったアイデア | AIが科学の探求領域そのものを広げた |
| ③ 計算資源=研究成果 | $18,000で800累計研究時間を実現 |
| ④ 再帰的自己改善の入口 | AIが自分自身の安全性を研究し改善する構造が始まった |
AIが自分自身の安全性を研究し、人間が見落とした脆弱性を発見し、人間が考えもしなかったアイデアを生み出す──Anthropicが恐れと驚嘆をもって予期していた「再帰的自己改善」の入口に、私たちは立っている。2026年はすでにいくつかの驚きを秘めていた。そして、それが近いうちに変わる気配はない。
コメント